4.2 数据集基本操作
4.2.1 简介
数据集是一个数据的集合,通常以表格形式出现。每一列代表一个特定变量。每一行都对应于某一成员的具体信息。
在Dataviz中,数据集是数据展现和数据的分析基础,数据集的主要作用是提供数据的模型,确定的维度和度量。所以,数据集中的数据就是数据源中原始的数据,是不需要进行聚合或统计处理的,在后边的数据展现和数据分析阶段再做数据的计算处理。
数据集属于项目资源,不可跨项目使用。
4.2.2 创建数据集
在项目资源页面,点击“建数据”,进入数据源管理页面:
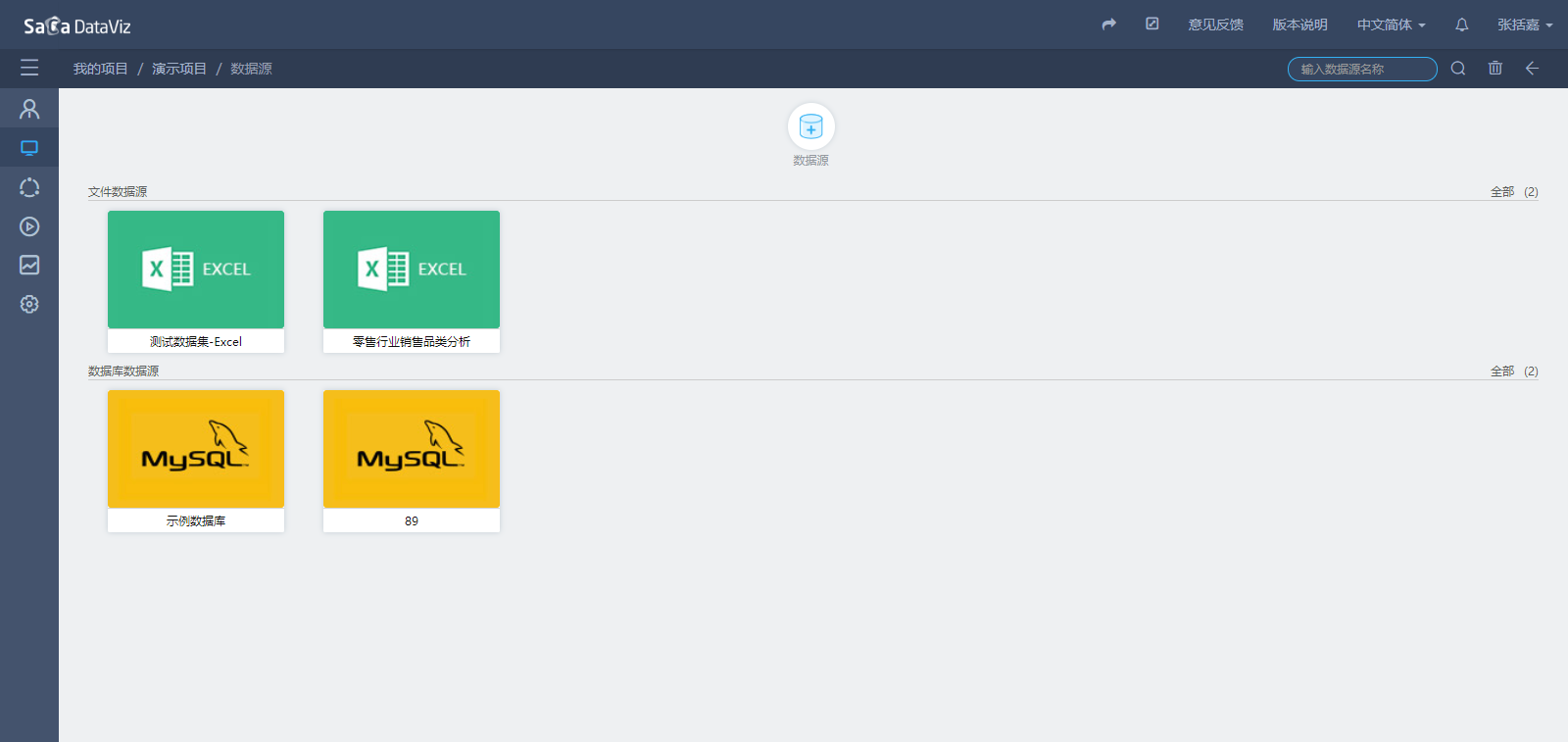
在数据源页面,点击任意一个数据源,即可进入到数据集创建页面,该数据集是依赖于所选择数据源的,如下图所示。
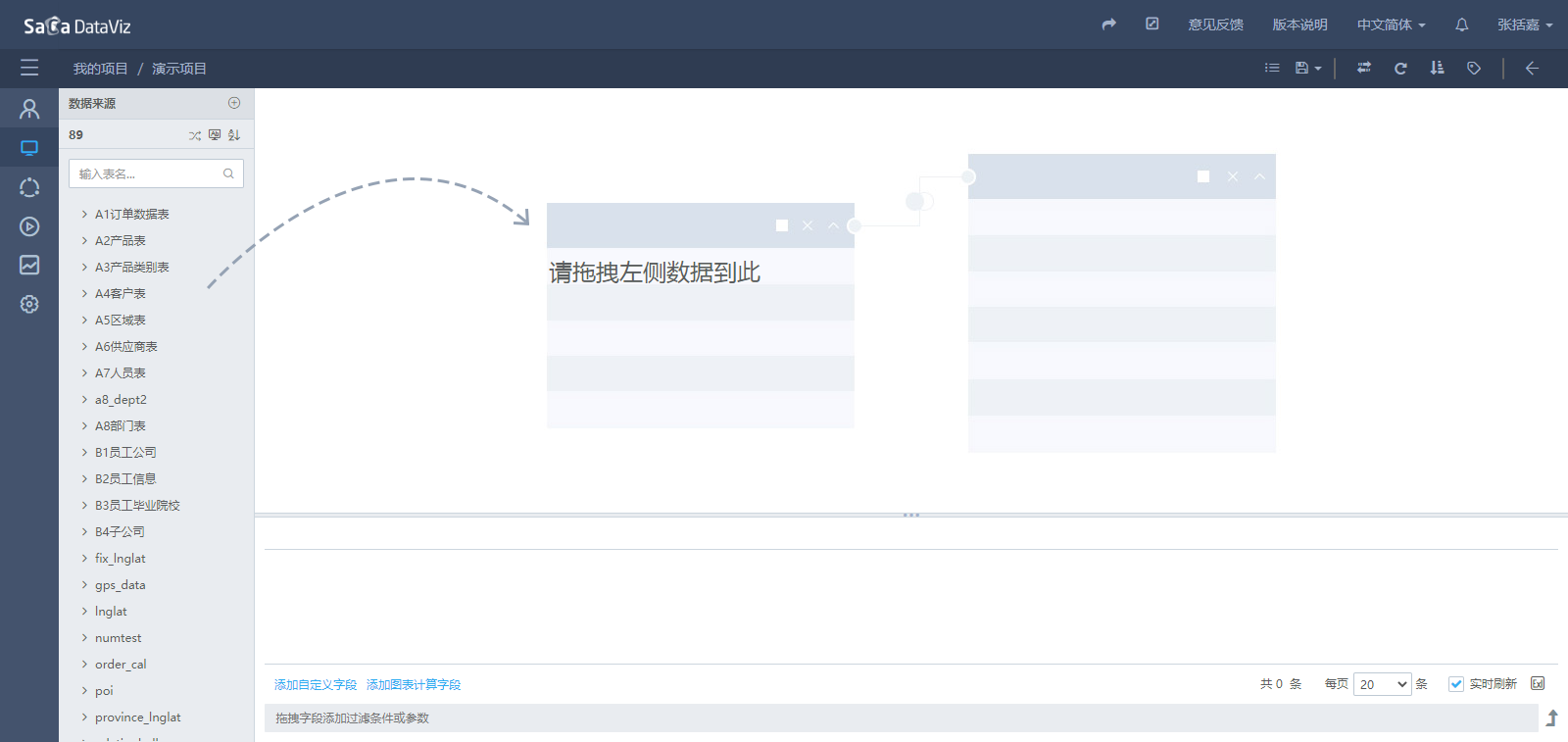
4.2.2.1 视图数据集
数据集默认页面是图形拖拽的方式创建的视图数据集。视图数据集的创建按照如下步骤进行。
拖拽表
页面左侧显示当前数据源下的所有数据表,可以拖拽数据表到数据集编辑区域,从而将数据表加入数据集。如下图所示:
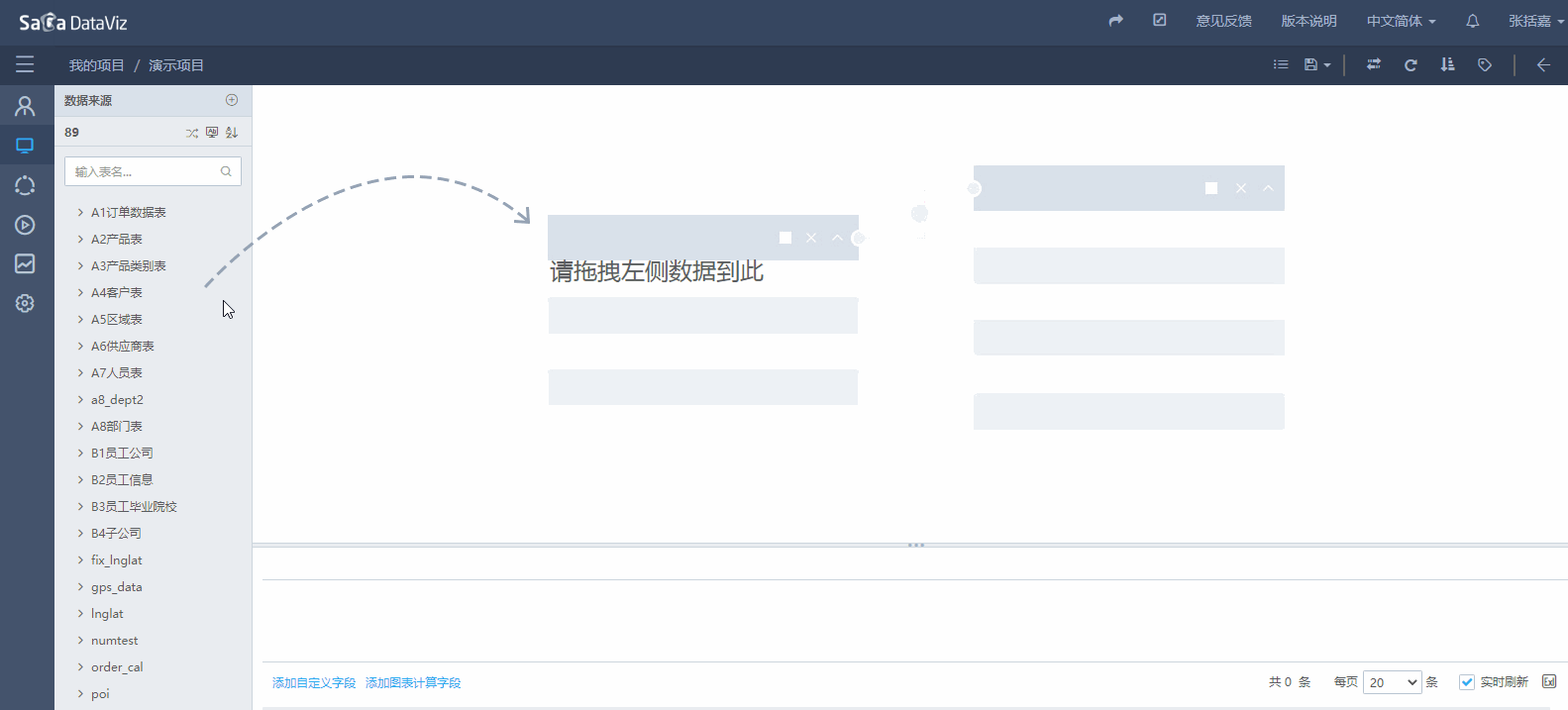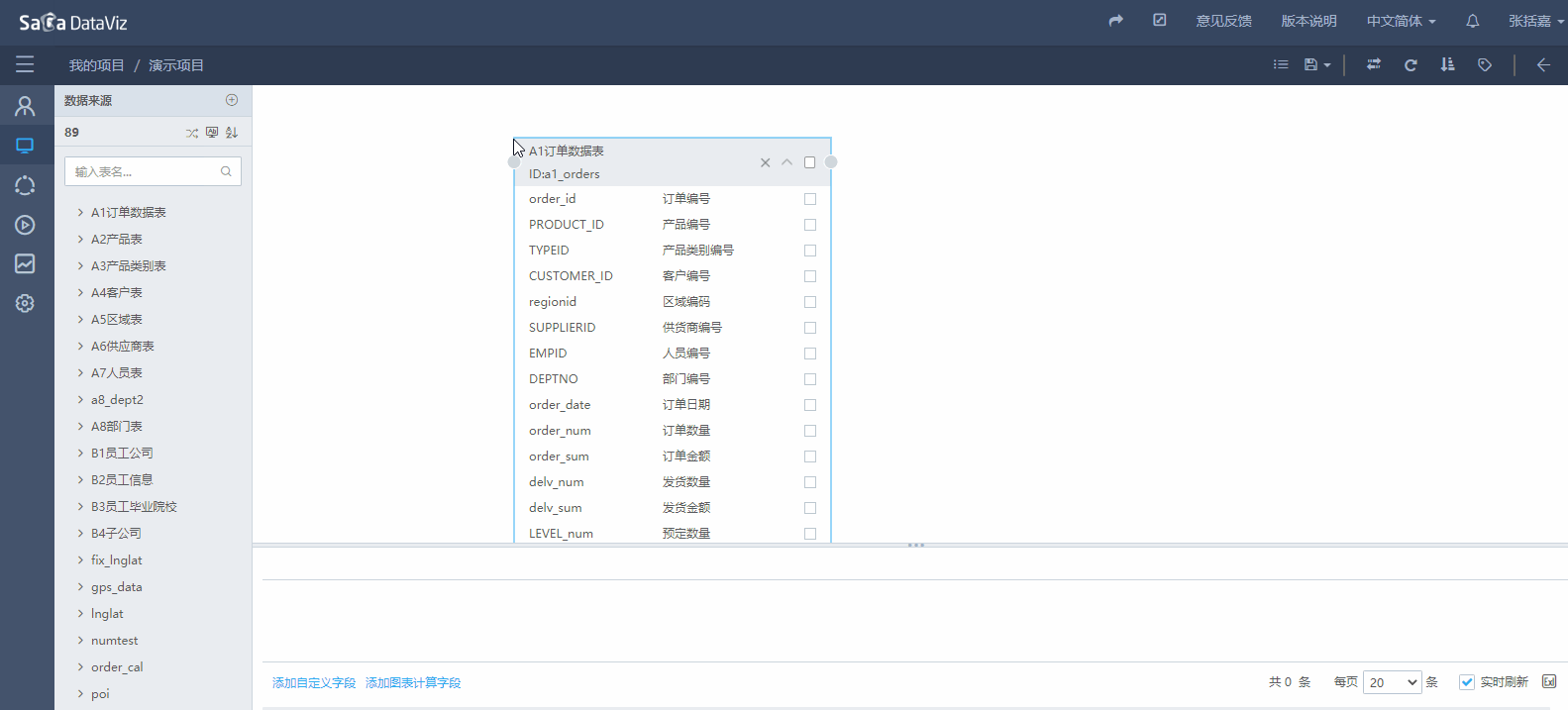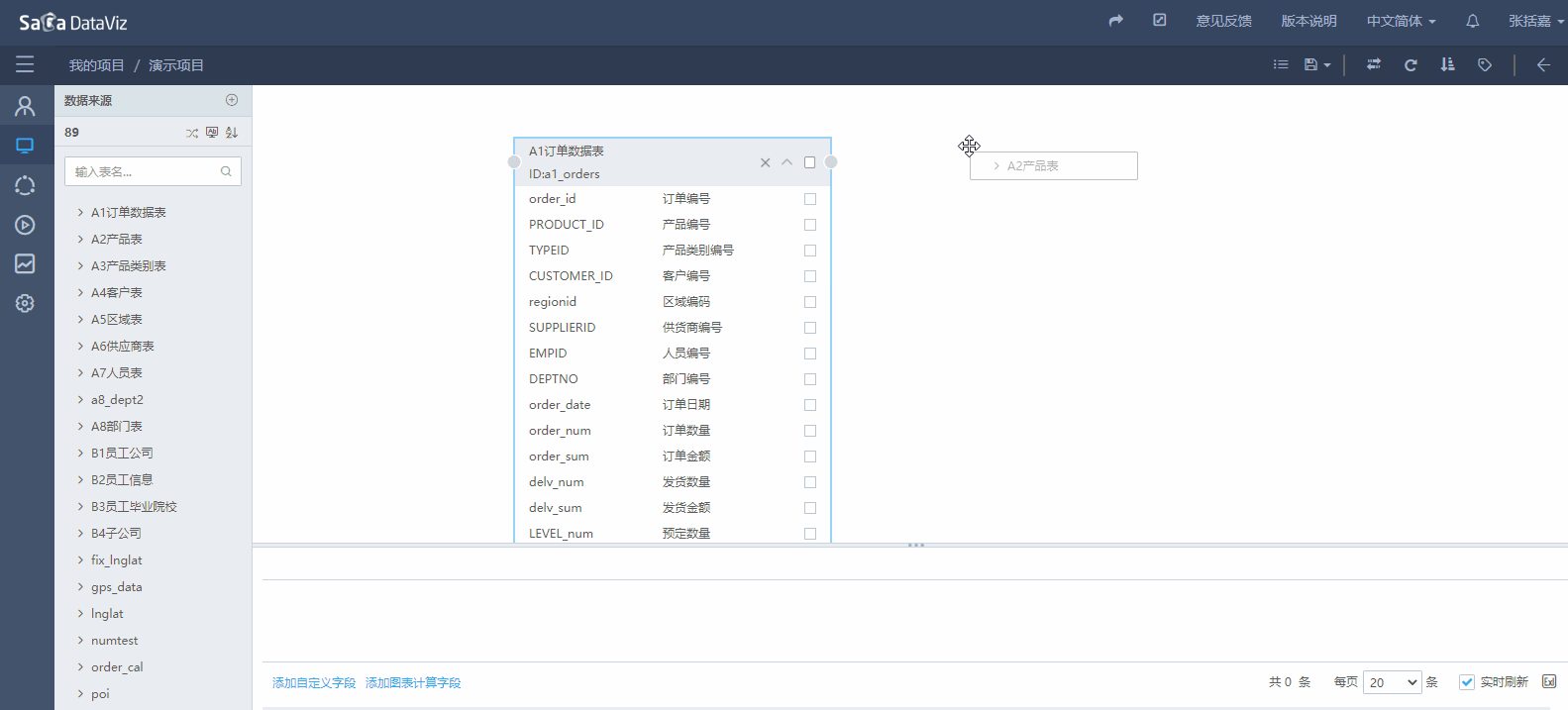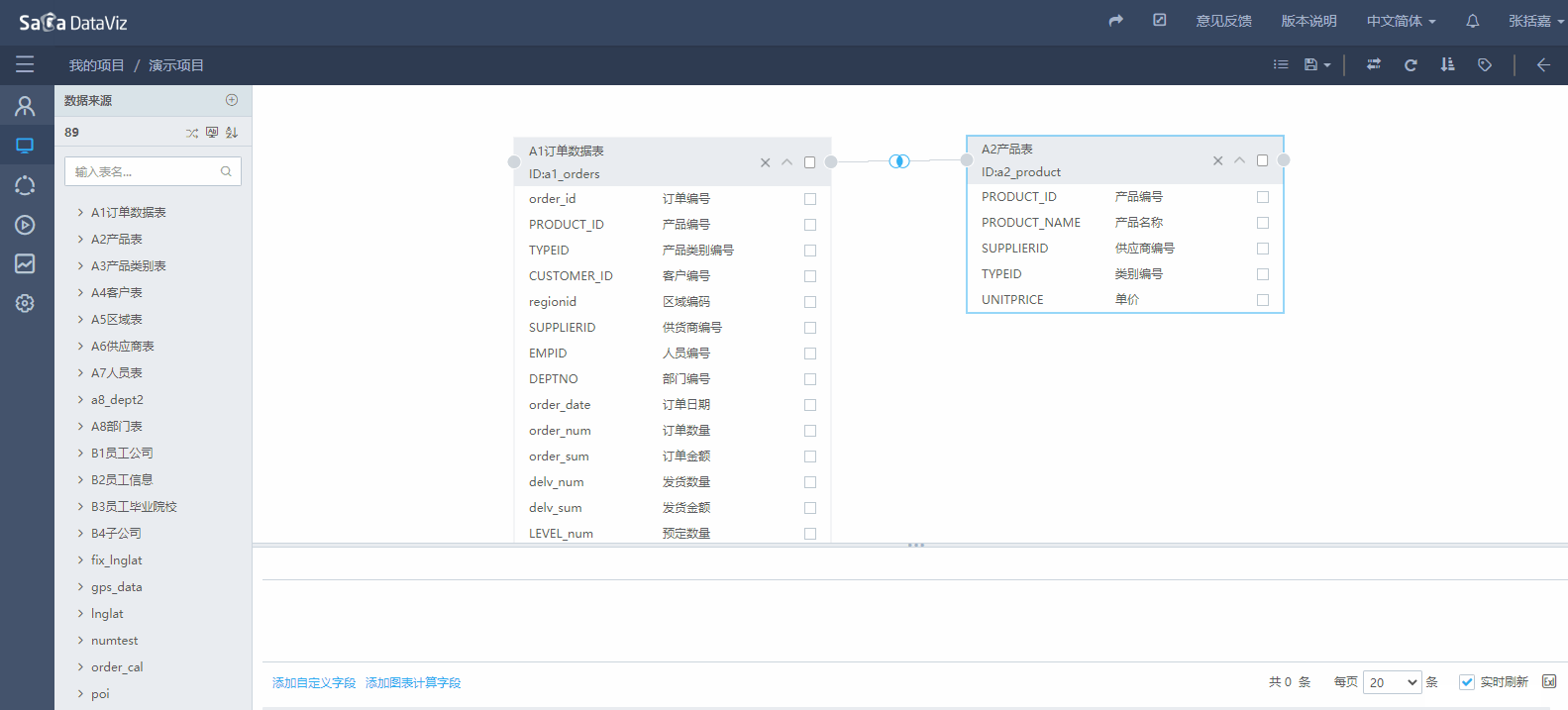
设置关联关系
如果数据集中需要引用多个数据表,则可以继续拖拽需要使用的数据表。多个表之间需要建立表间的关联关系。
如果两个表之间存在主外键关系,系统会自动根据主外键创建表之间的关联;如果表之间没有主外键,则会根据相同的字段名自动建立关联关系,如上图所示。如果要修改字段的关联关系,可双击原点进行编辑修改,如果要删除需要选中原点后按键盘的Del。
如果无法自动创建表间的关联关系就需要手动创建。手动建立关联关系,需要点击表一侧的圆点,按下鼠标左键,拖拽到另一个表的圆点上,松开鼠标左键,会出现弹出设置关联关系的窗口,选择关联方式以及关联字段,再点击确认按钮后即可完成关联关系的创建,如果要再次编辑,需要先选中原点后在操作。如下图所示:
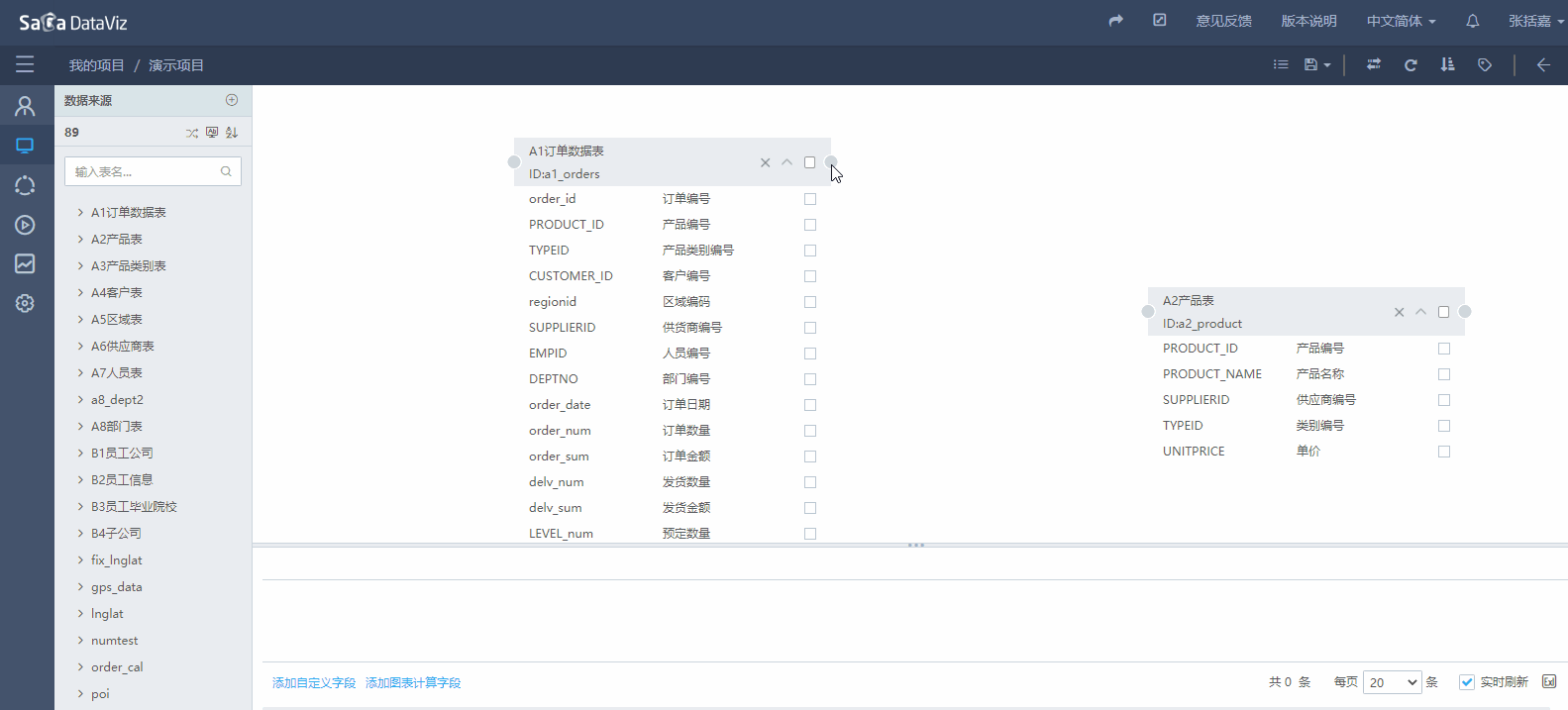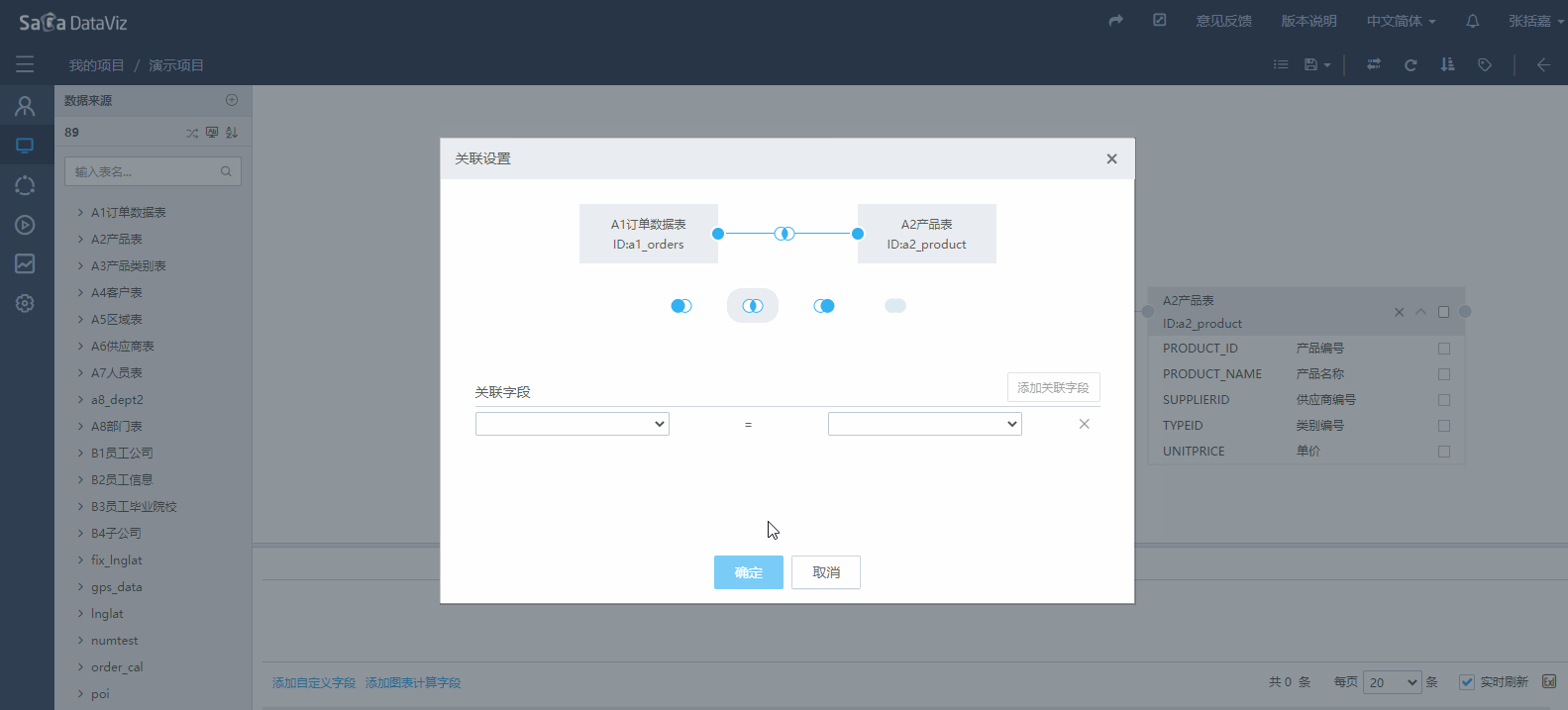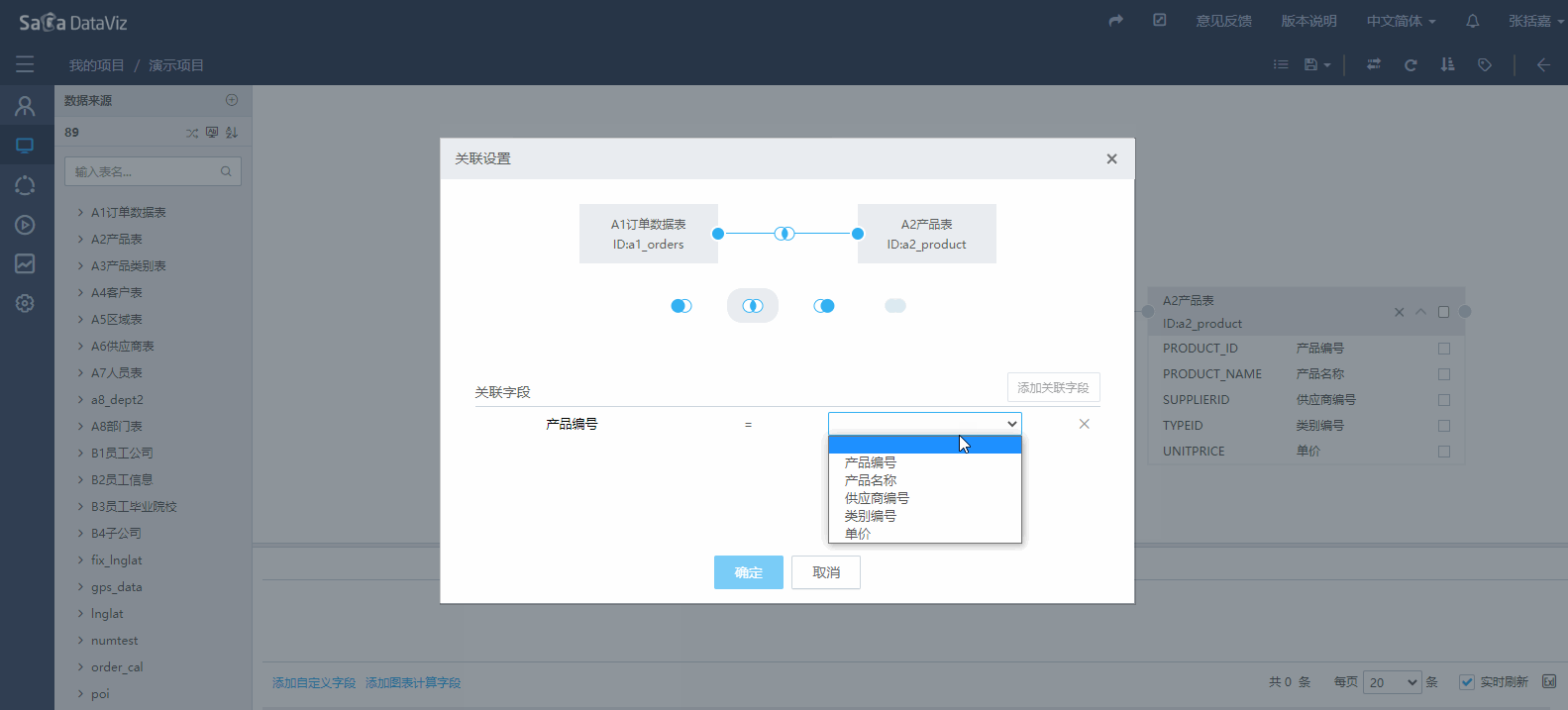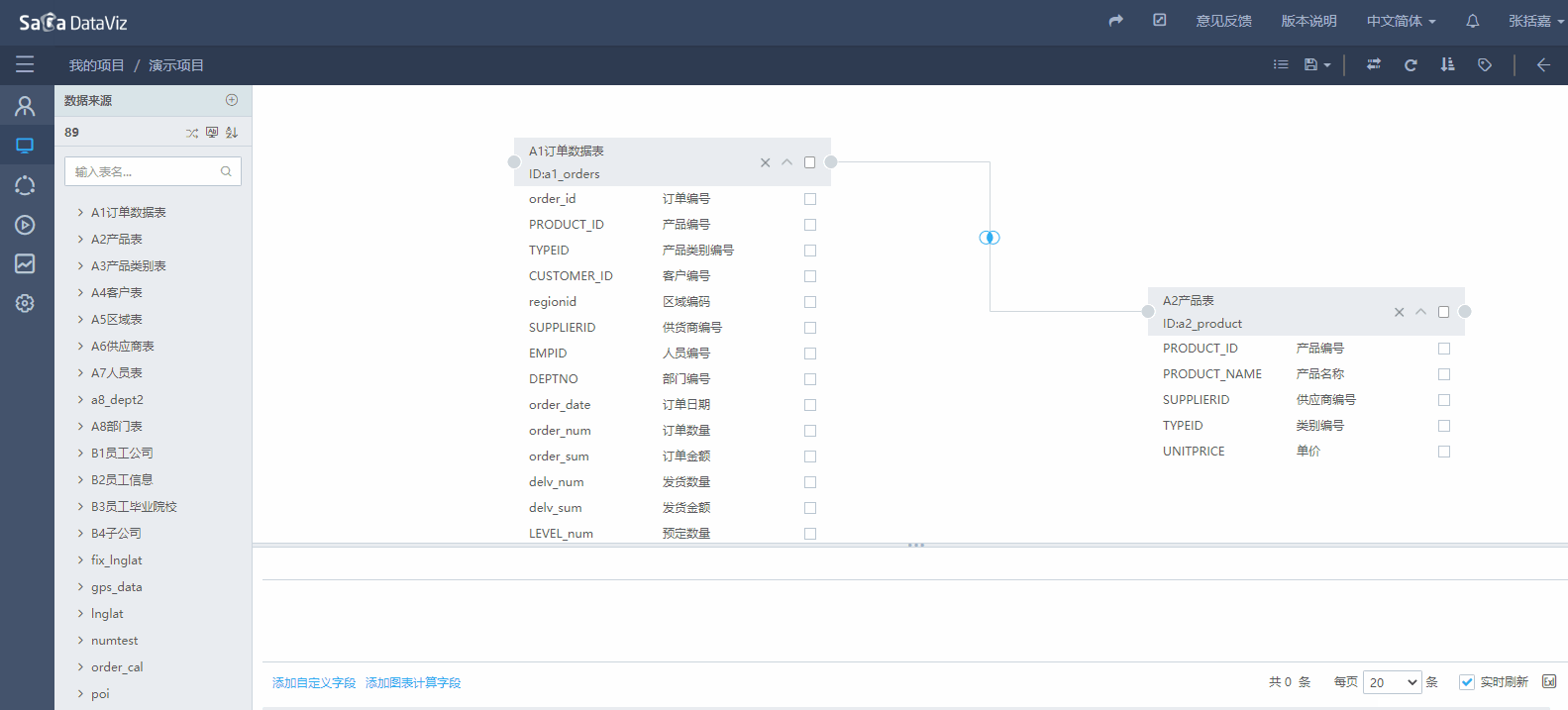
若需要删除数据表间的关联关系,首先点击关联关系图标选中关联关系,然后按键盘的Delete键即可删除。
双击表间的关联关系可以弹出编辑窗口,编辑关联方式和关联字段。
勾选字段
在表中选择需要的字段,在页面下方的区域可以预览字段的数据,如果数据加载较慢可取消勾选实时刷新复选框。如下图所示:
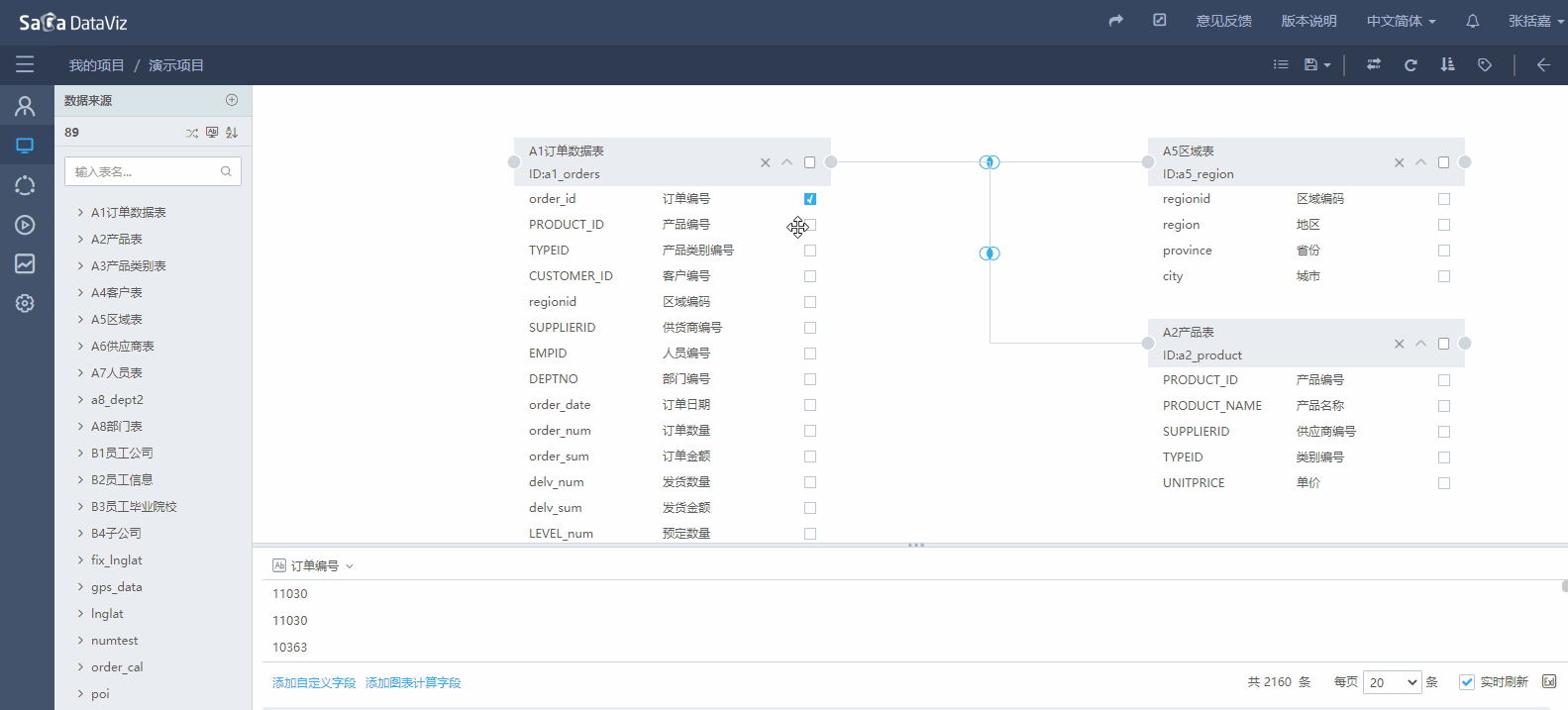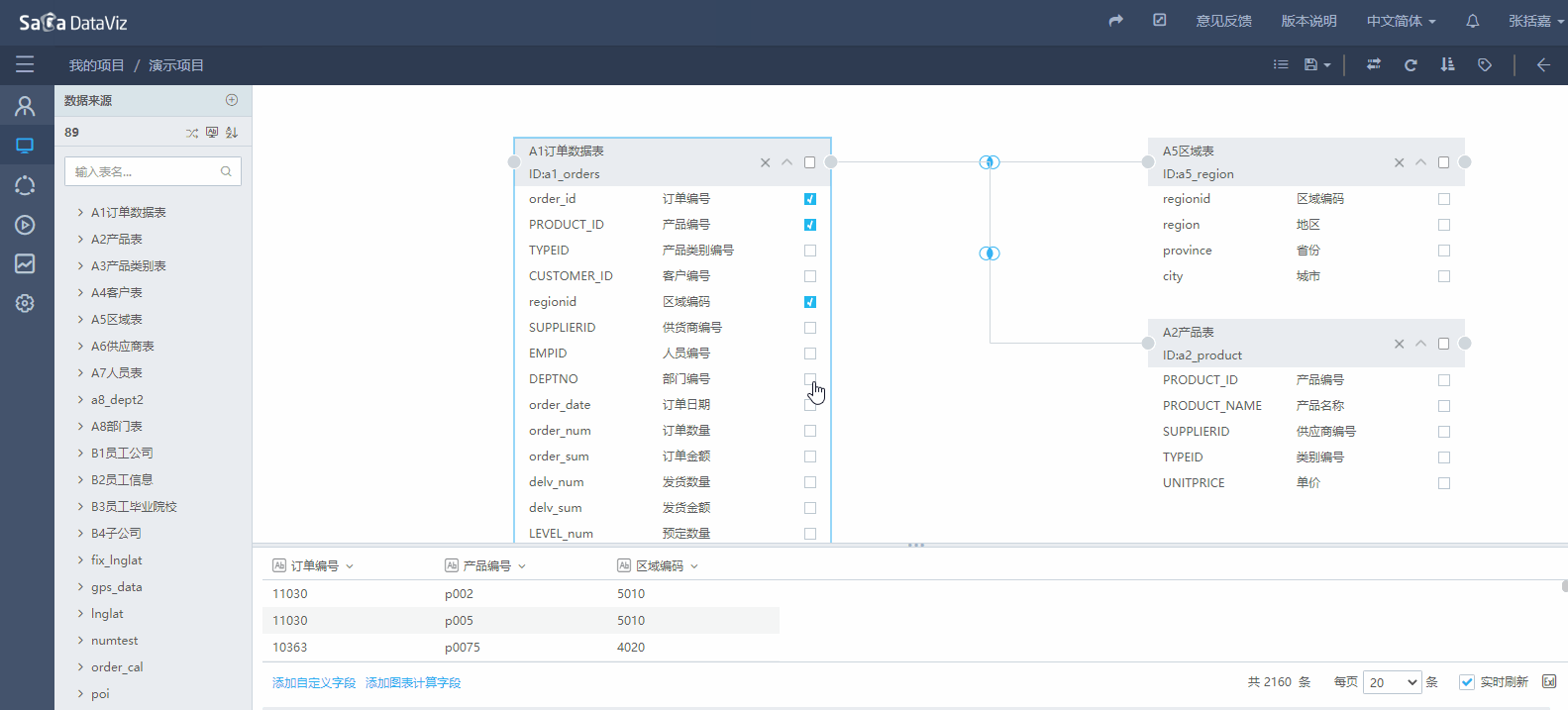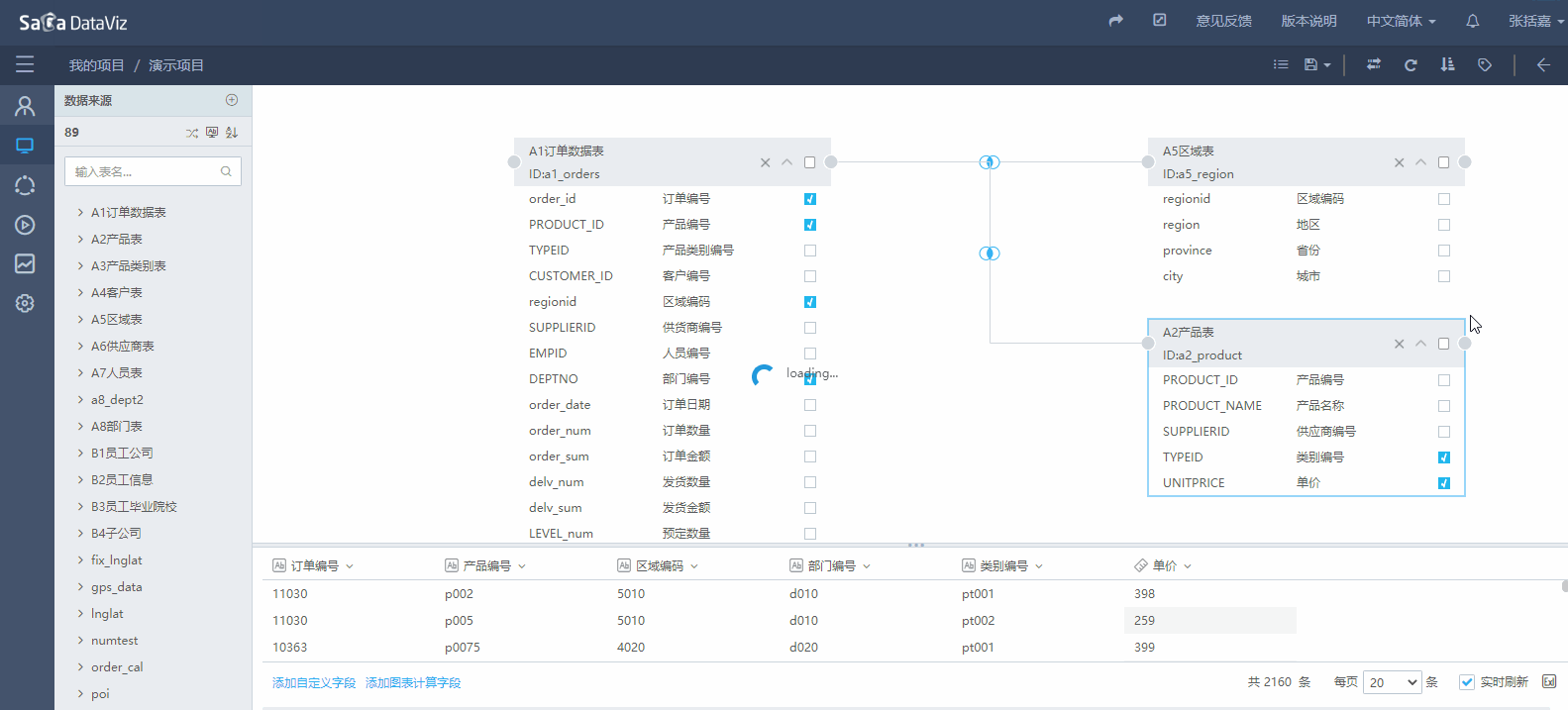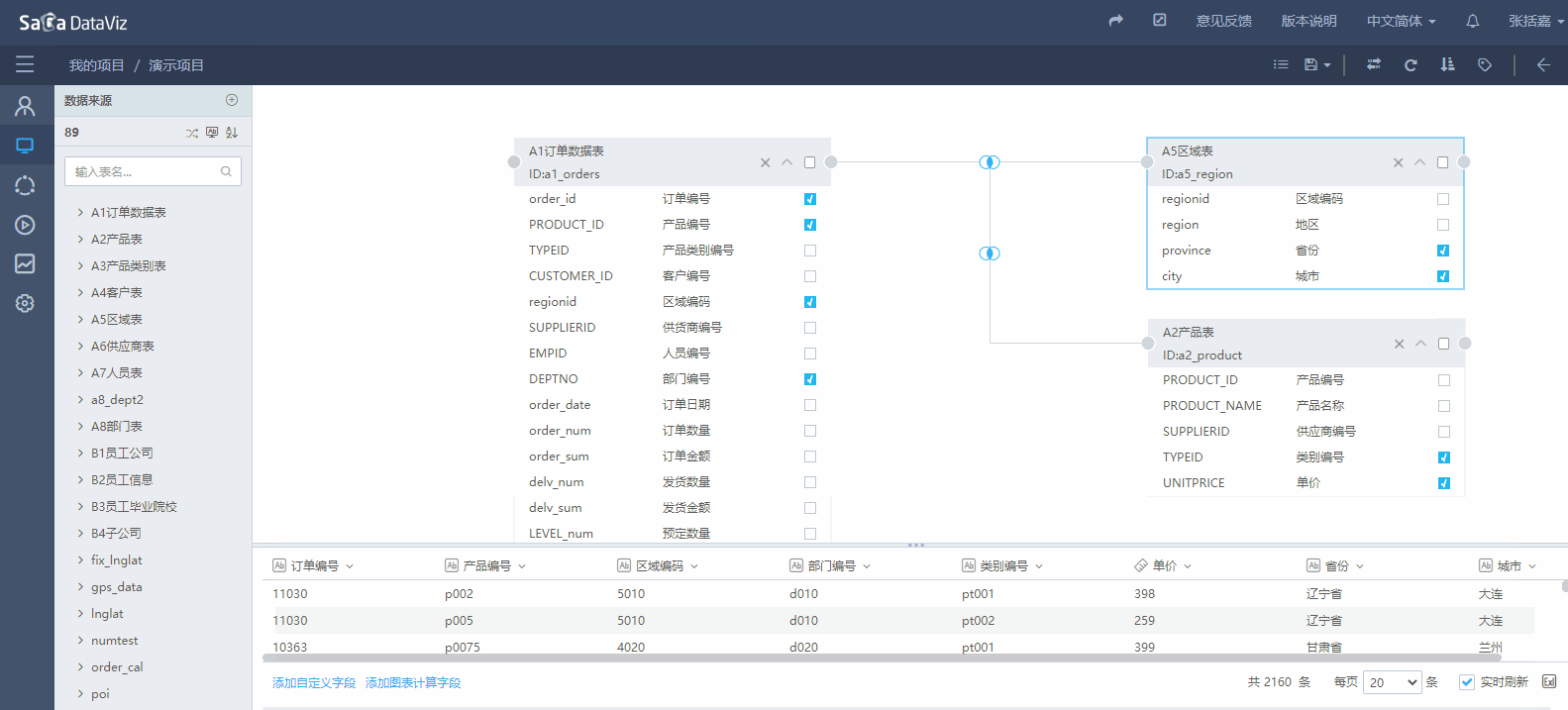
自定义字段
在数据集编辑页面除了可以勾选数据源的表中的字段外,还可以根据表中的字段自定义数据集字段。
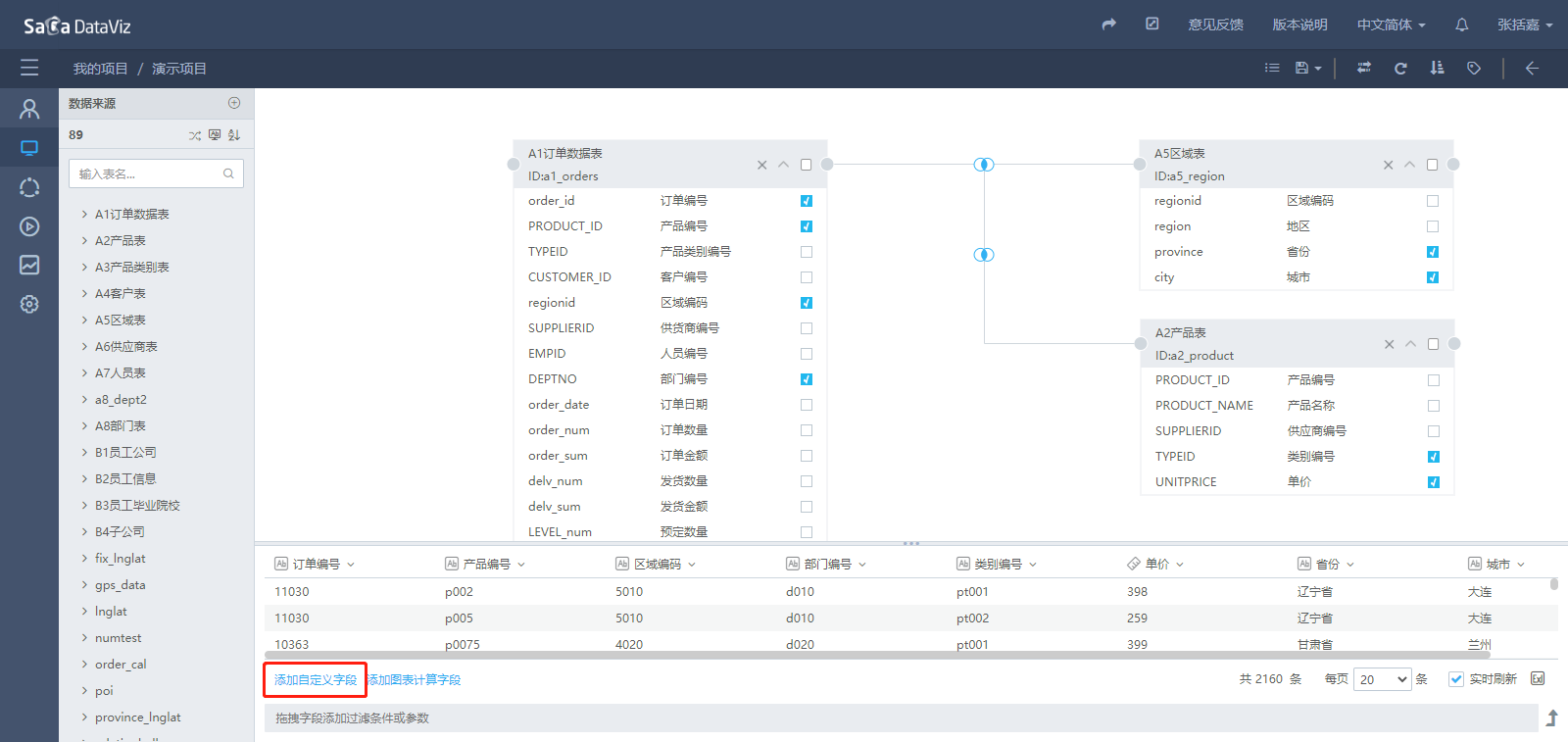
点击页面下方的“添加自定义字段”,弹出自定义字段编辑窗口,在窗口中可以通过双击和拖拽的操作方式把字段和公式添加到字段内容区,组成新的计算字段,点击公式,可以在右侧查看公式的详细说明。具体的操作过程如下图所示。
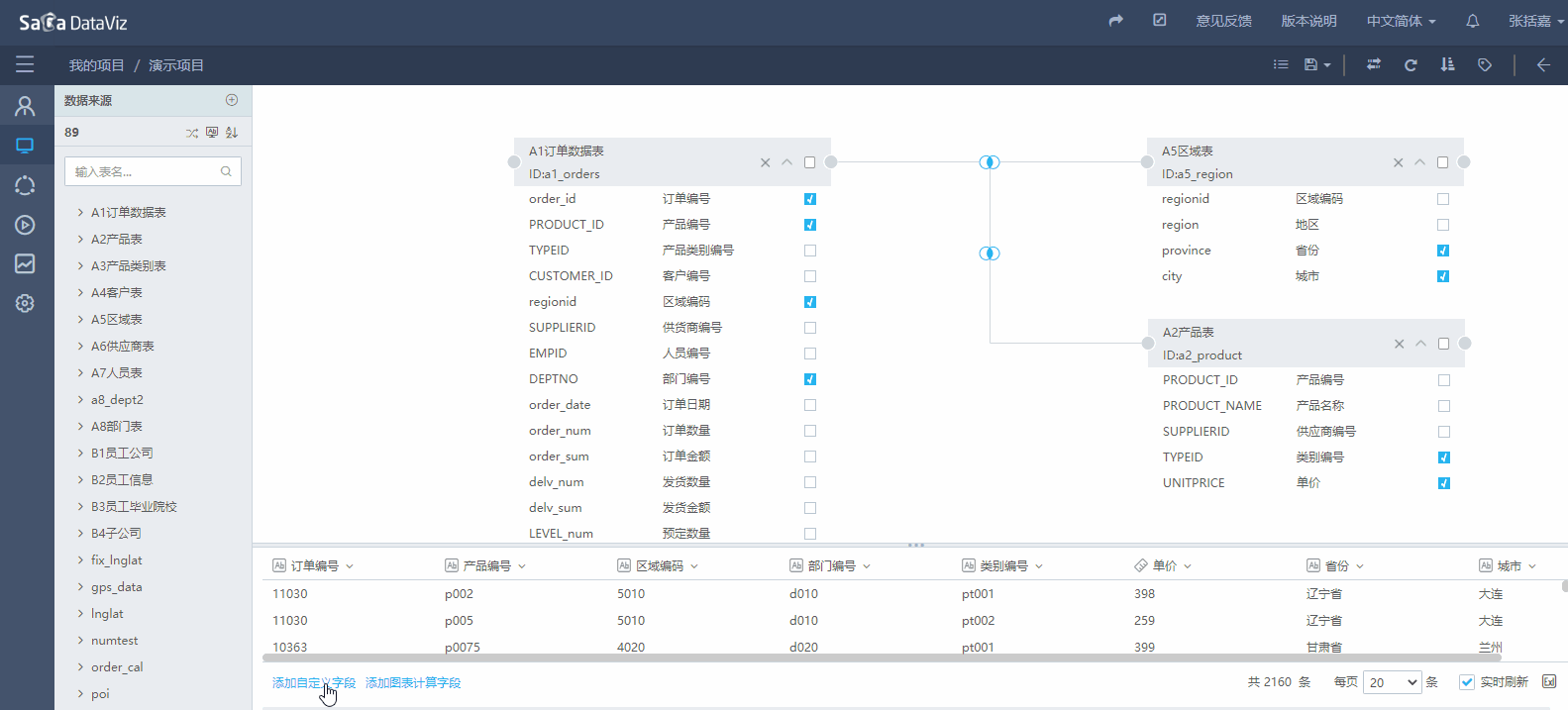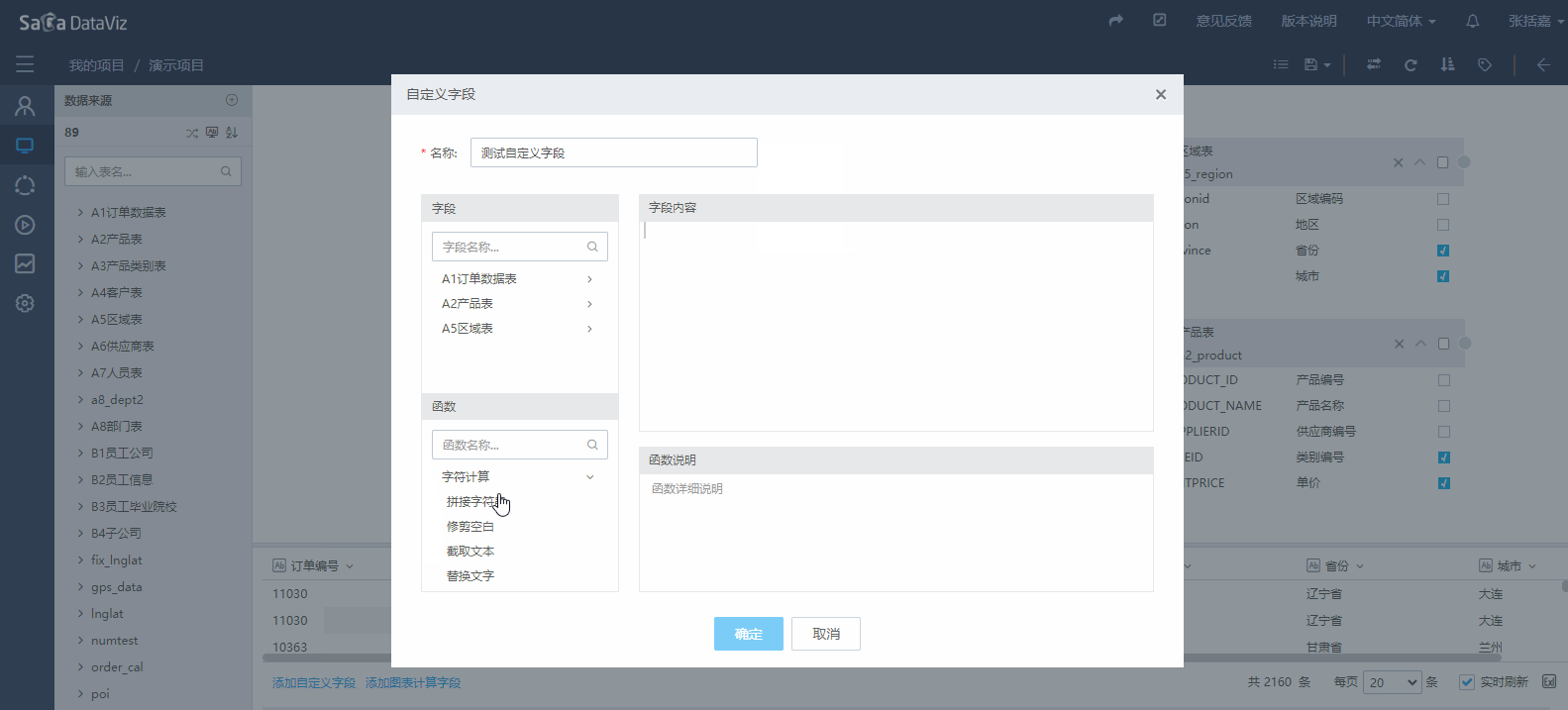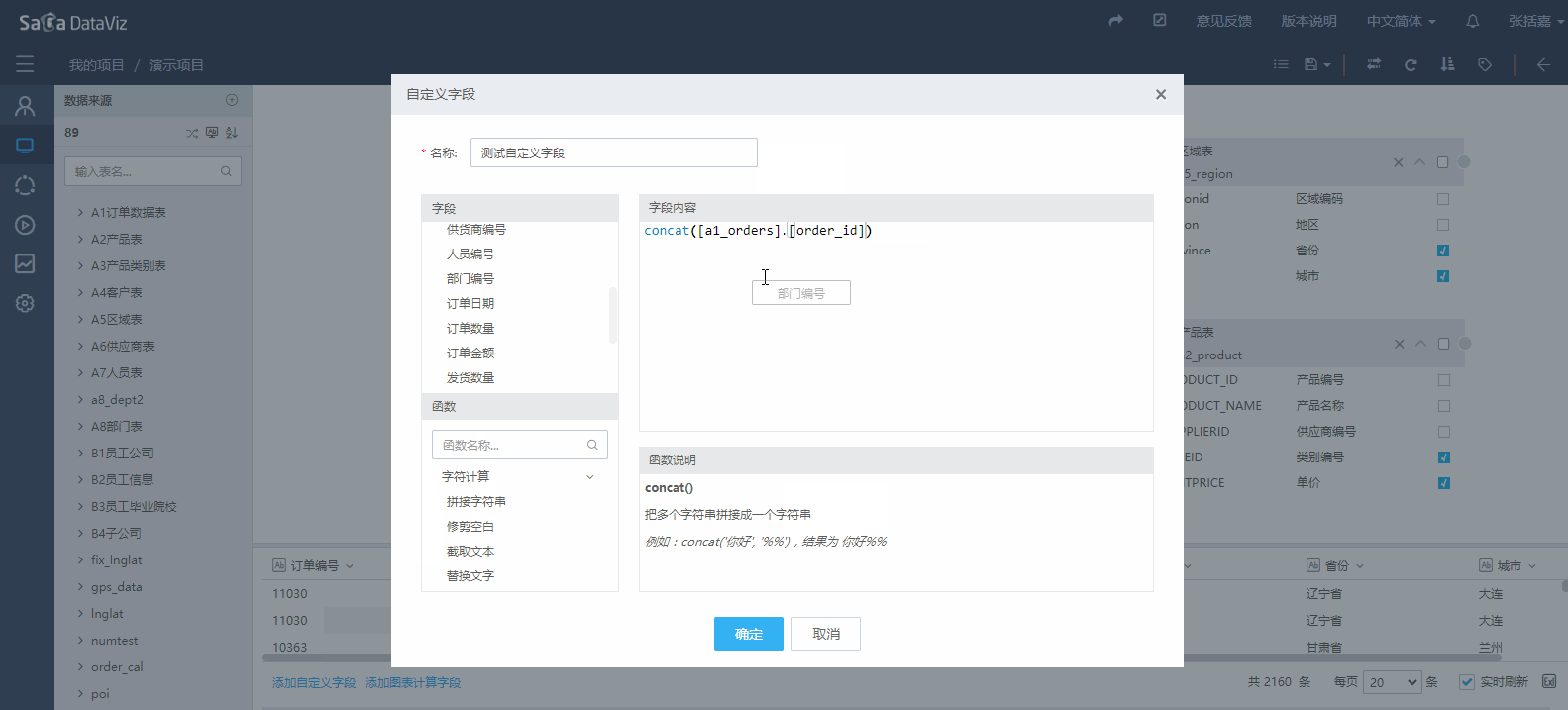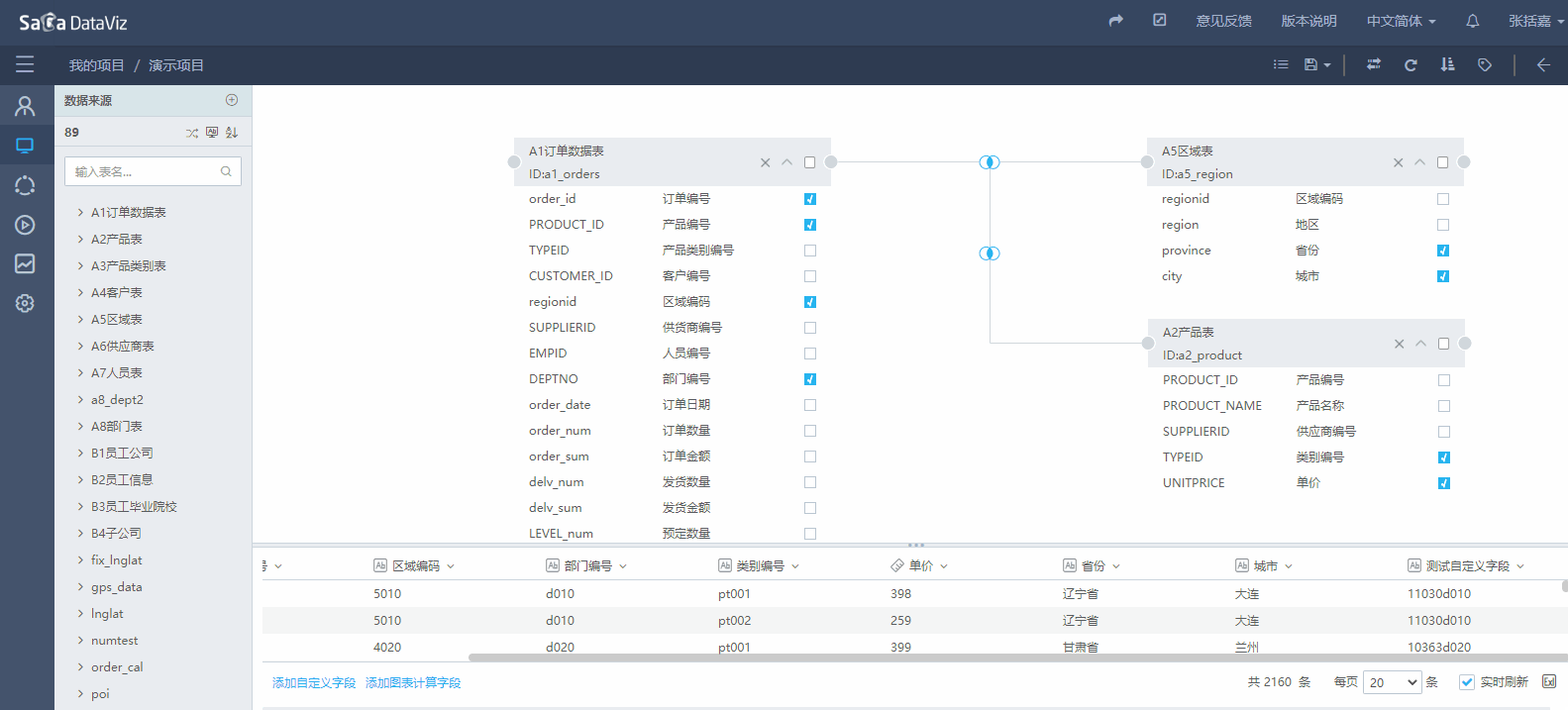
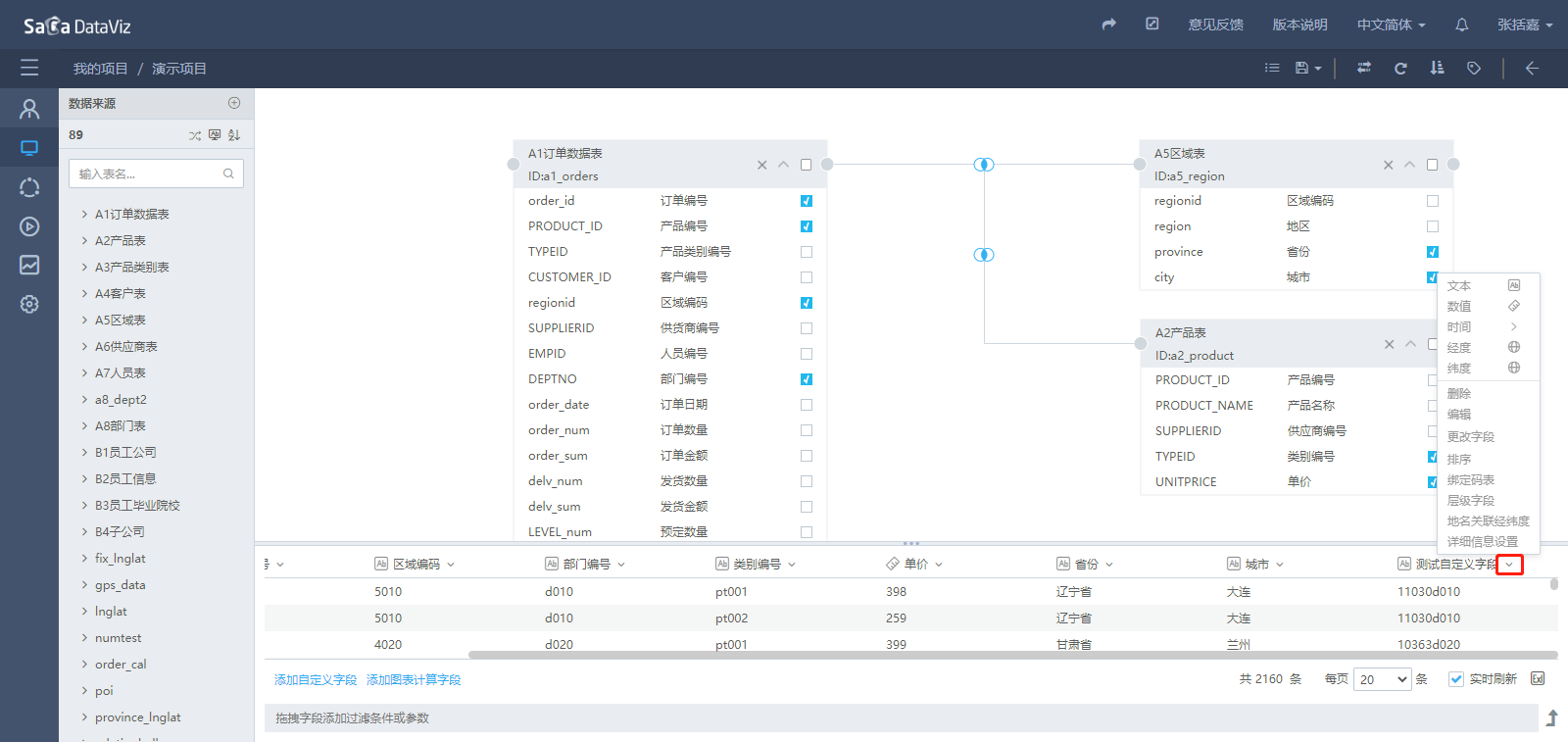
如果需要对自定义字段进行删除、重命名、更改等操作,请点击该字段右侧的箭头,在列表中选择希望进行的操作,如下图所示。
如需添加常量字符串,可直接在字段内容中编写。
字段类型转换
在数据集预览区域,每个字段右侧的下拉菜单中提供了数据字段的类型转换功能。对于以字符串类型存储的数值字段可在此处转换为数值和日期类型,对于数值类型的字段可在此处转换为字符串。后续计算以转换后的类型为准。
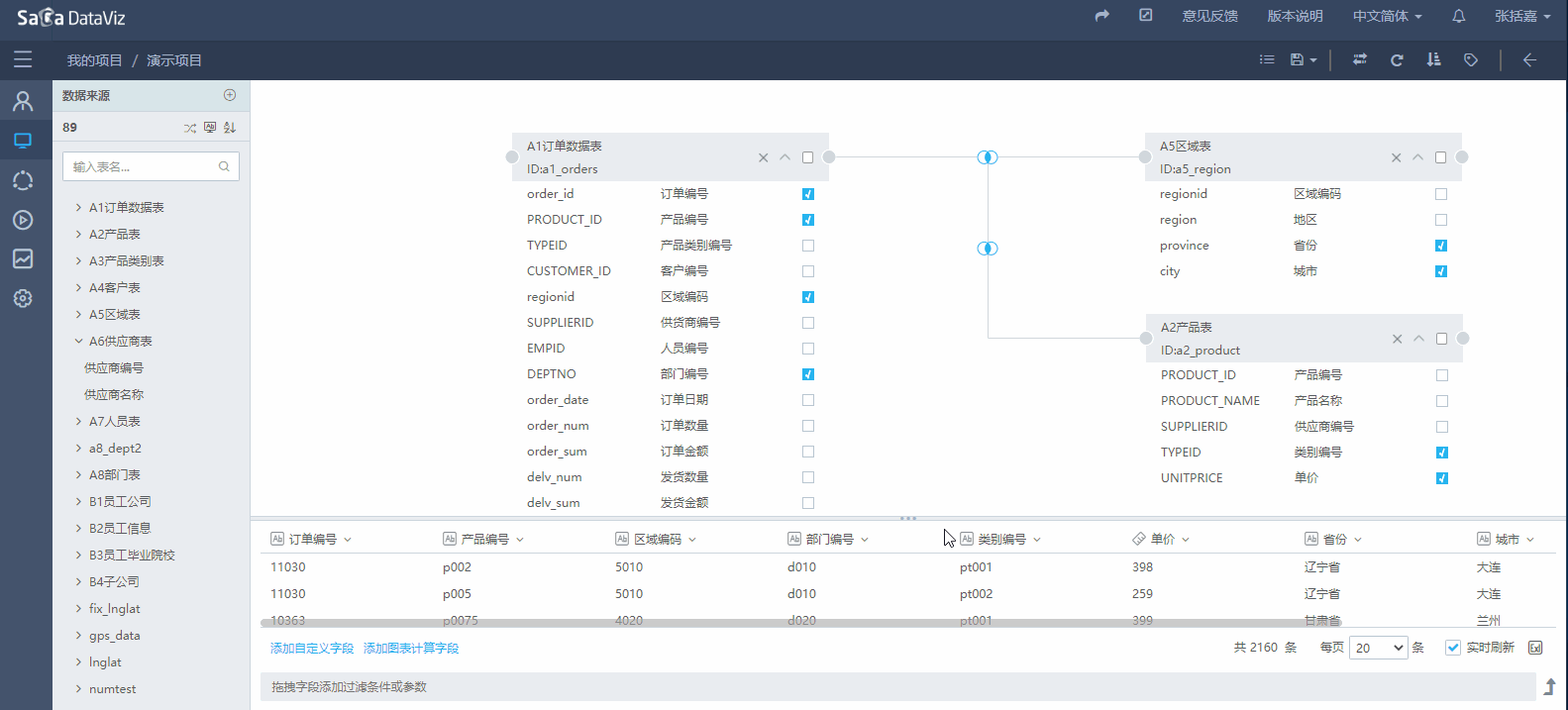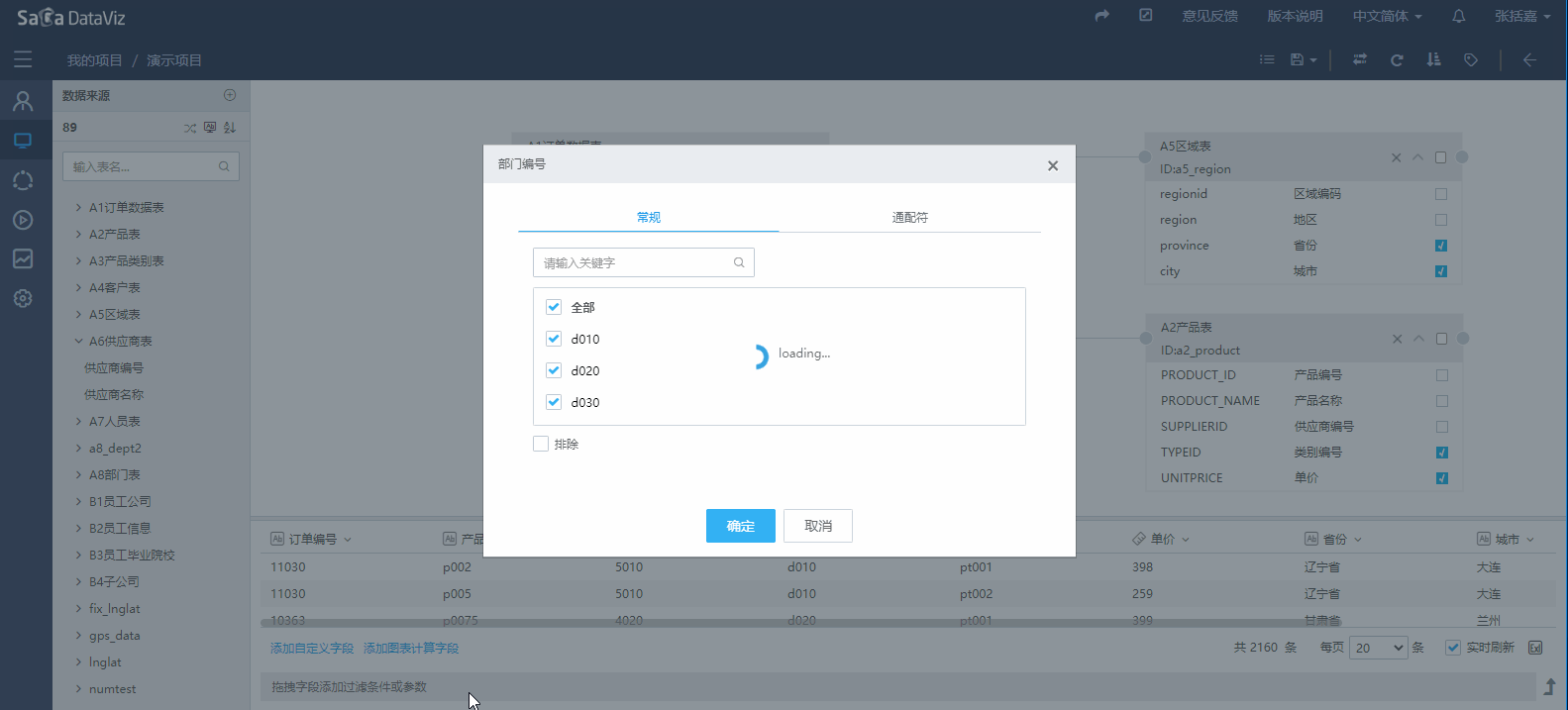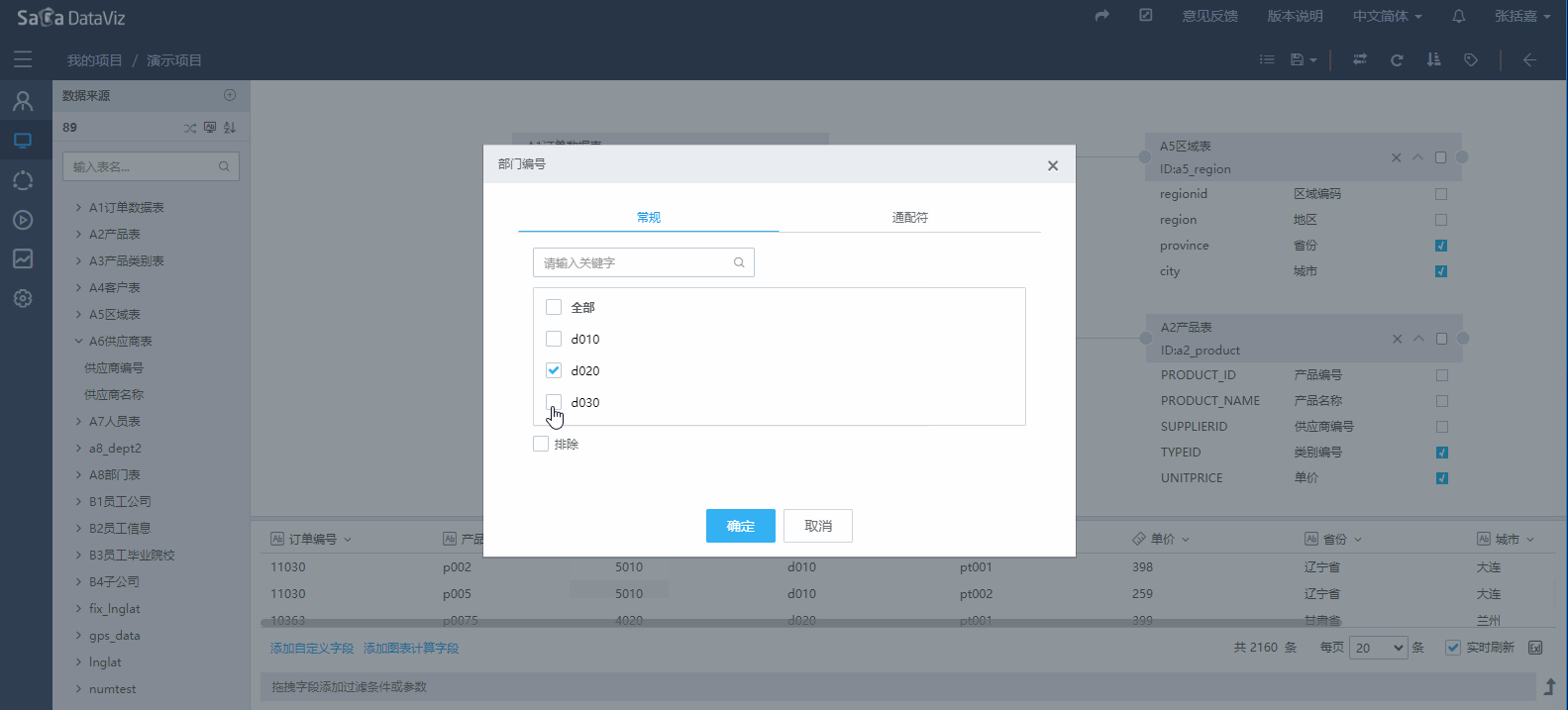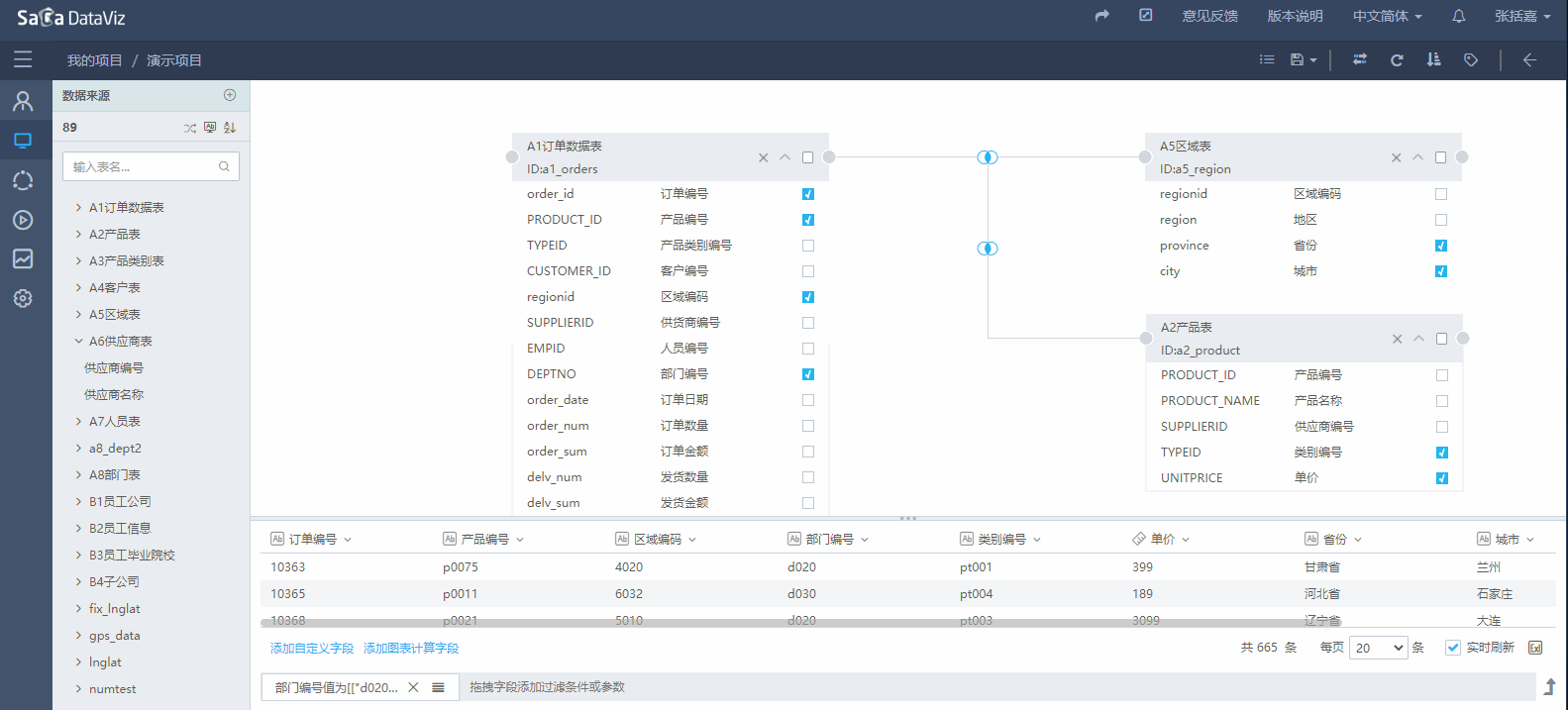
设置过滤条件
如果需要对数据集的查询范围做限制,可以通过将数据集字段拖拽到下方的过滤区域进行数据的过滤,如下图所示。
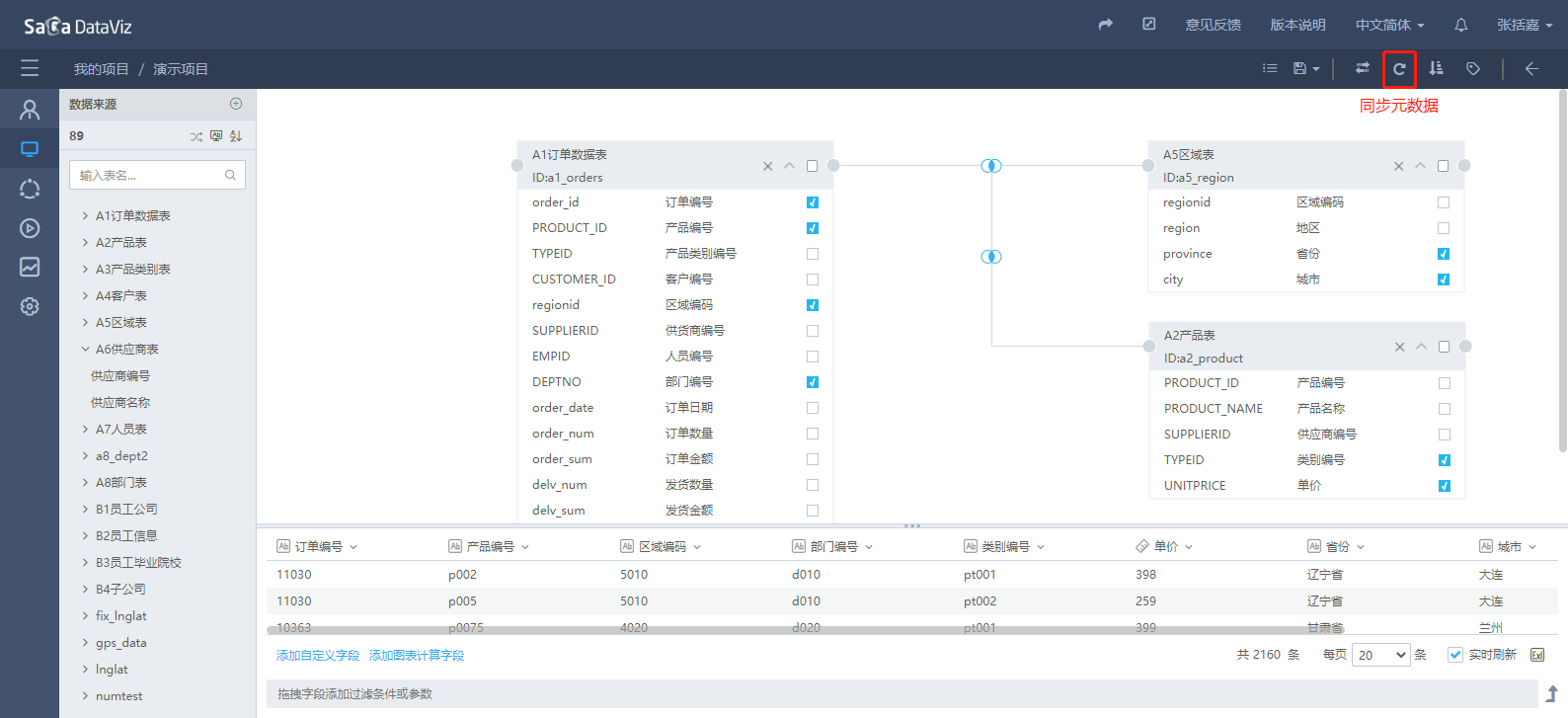
同步元数据
如果数据源中的表的字段发生了变化,可以点击右上角的同步元数据按钮进行元数据的更新。
多数据源
如果DataViz服务的计算资源充足,DataViz能够支持跨数据源的数据集。使用方法是点击左侧数据来源旁边的 + 号,此时会弹出数据源选择,选择一个数据源确定,左侧即会新增一个数据源抽屉。用户可以点击数据源名,打开指定的数据源抽屉,拖拽表到编辑区域。具体的操作如下图所示。
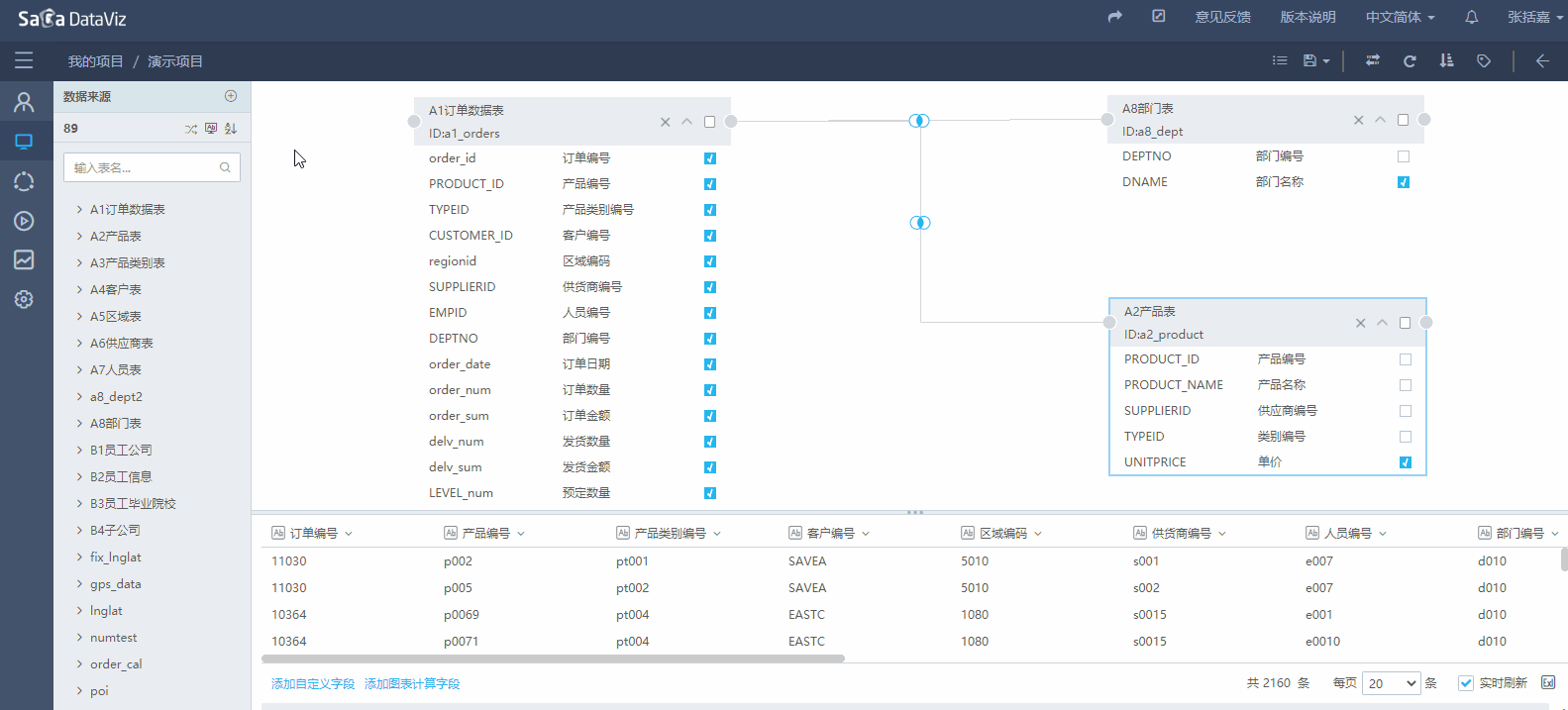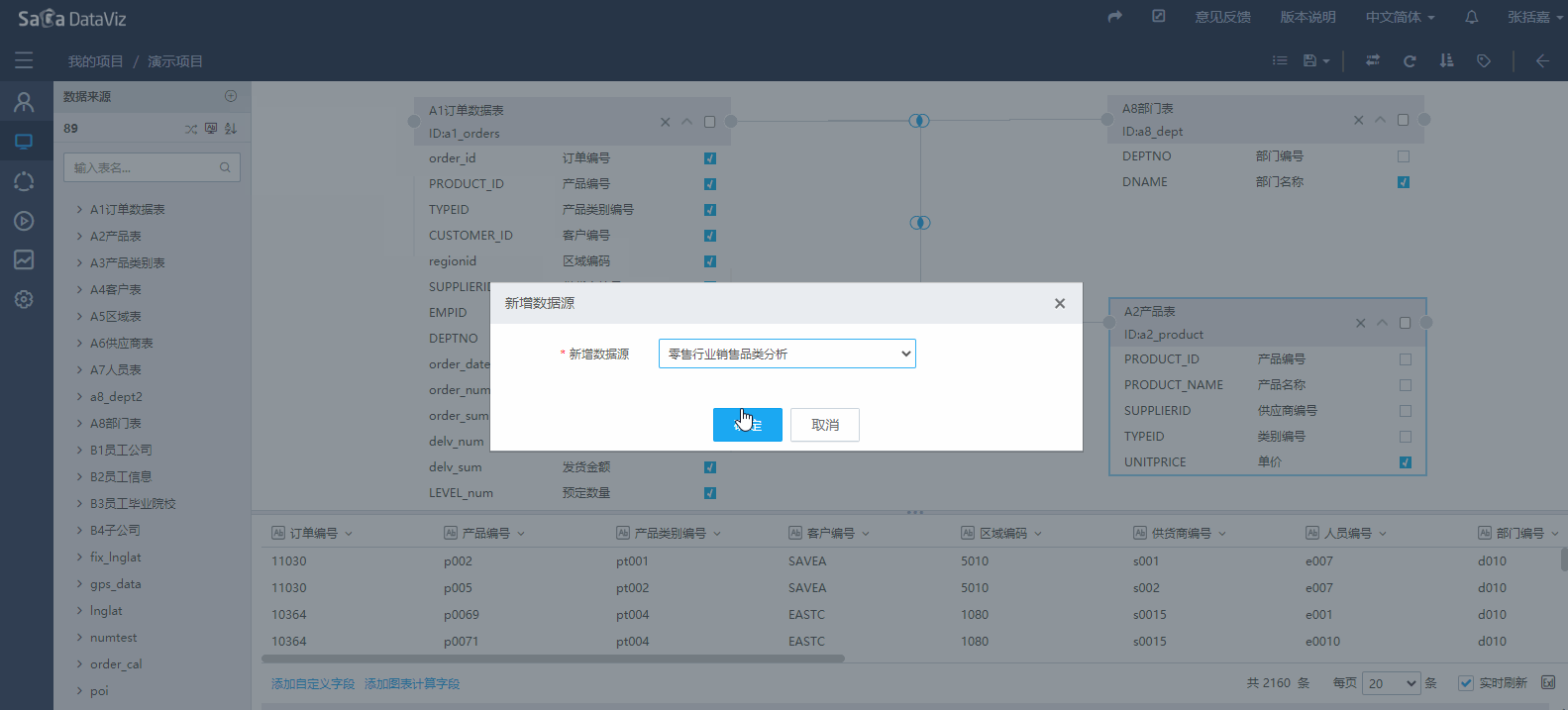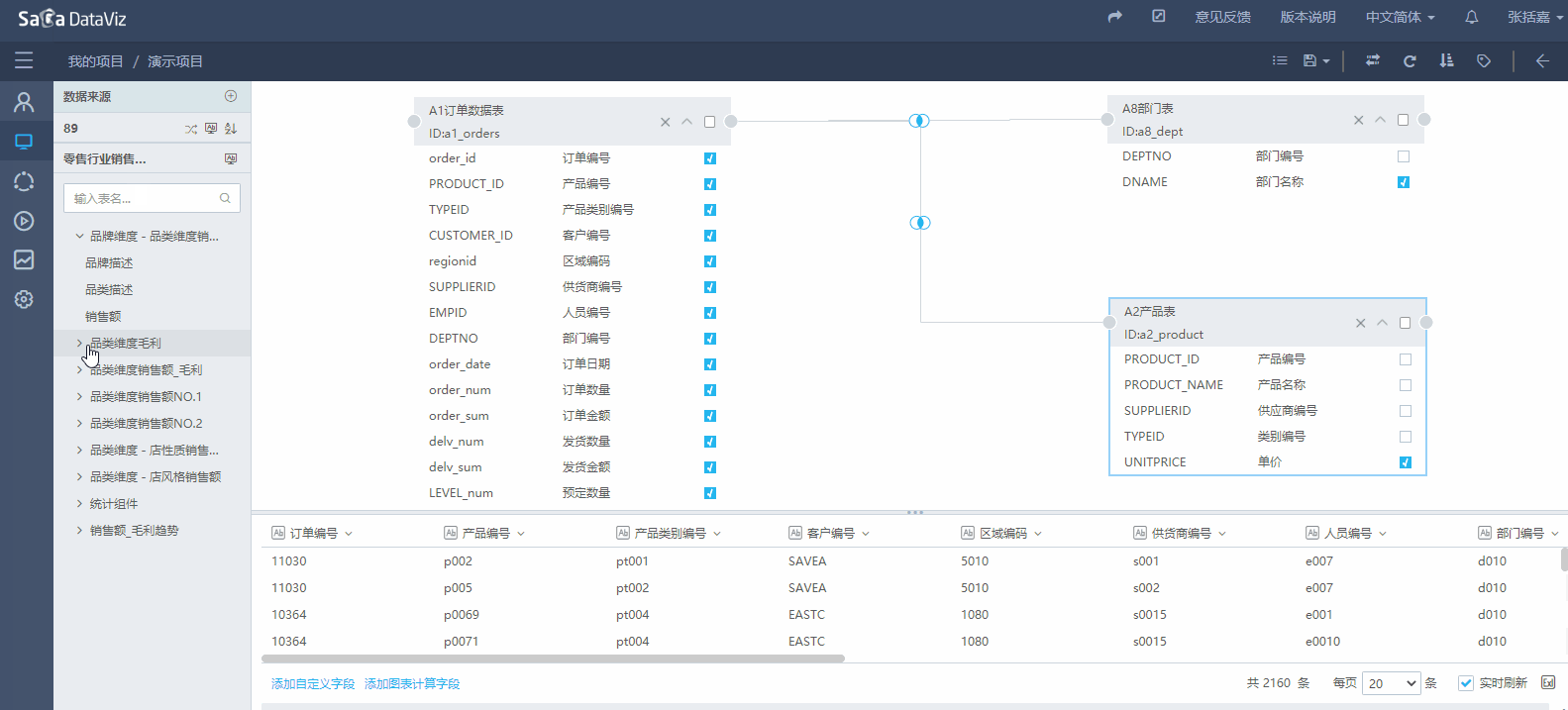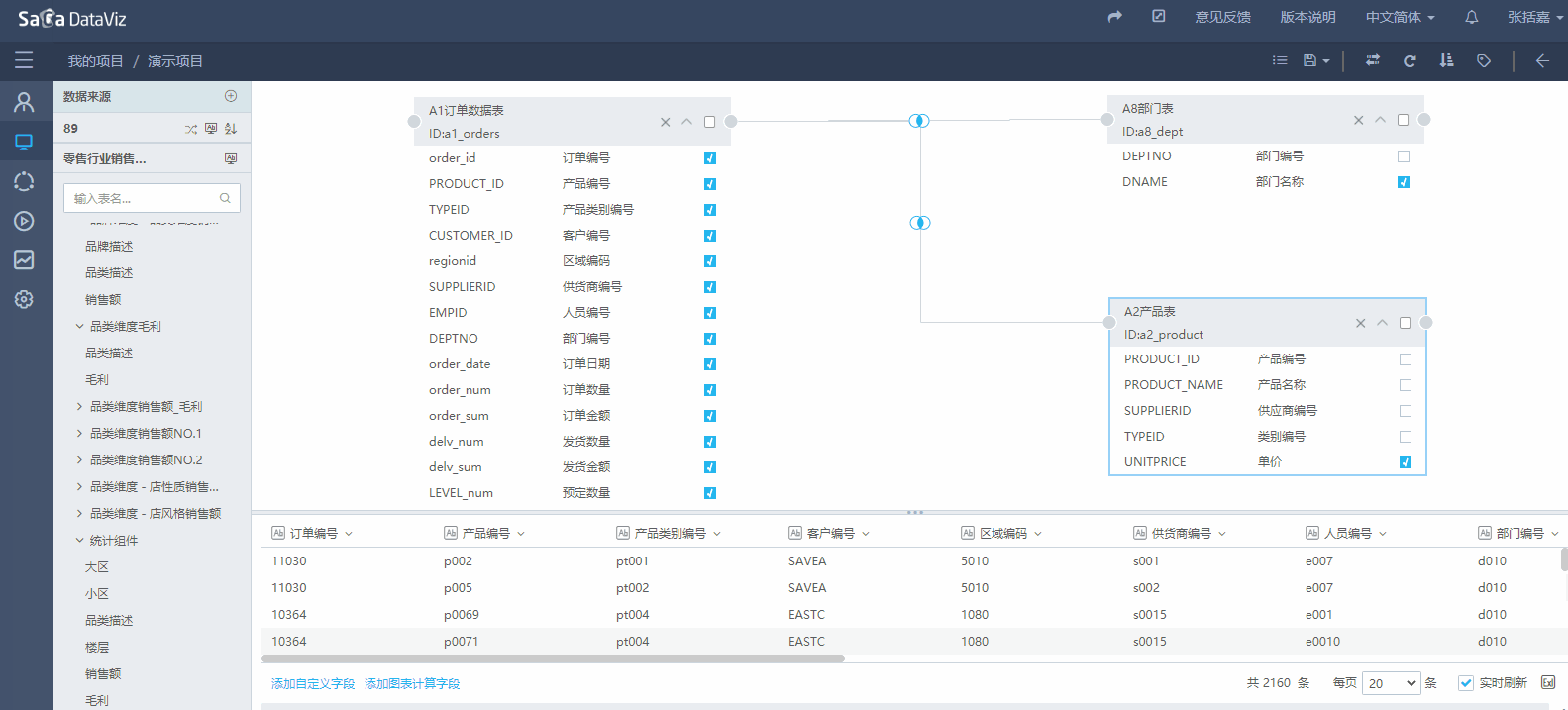
【注意】不能关联来自不同数据源,但表名、Schema、Catalog完全相同的表。
一旦在数据集中拖拽了来自多个数据源的表,该数据集将变为多数据源模式,该数据集及使用它的图表在使用自定义字段时将仅限于使用DataViz中提供的函数进行计算,且无法将字符串转为时间。
多数据源计算需要更多的服务器资源。当数据源表数据量较大,服务器计算资源相对不足时,多数据源数据集可能会出现执行缓慢或执行失败。
4.2.2.2 SQL数据集
SaCa DataViz支持通过编写SQL代码的方式创建数据集,为具有开发能力的用户提供更高的自由度。SQL语法以具体连接的数据源为准。
【注意】视图数据集和SQL数据集是相互不兼容的,不能相互转化,每个数据集只能选择一种方式进行数据集创建。
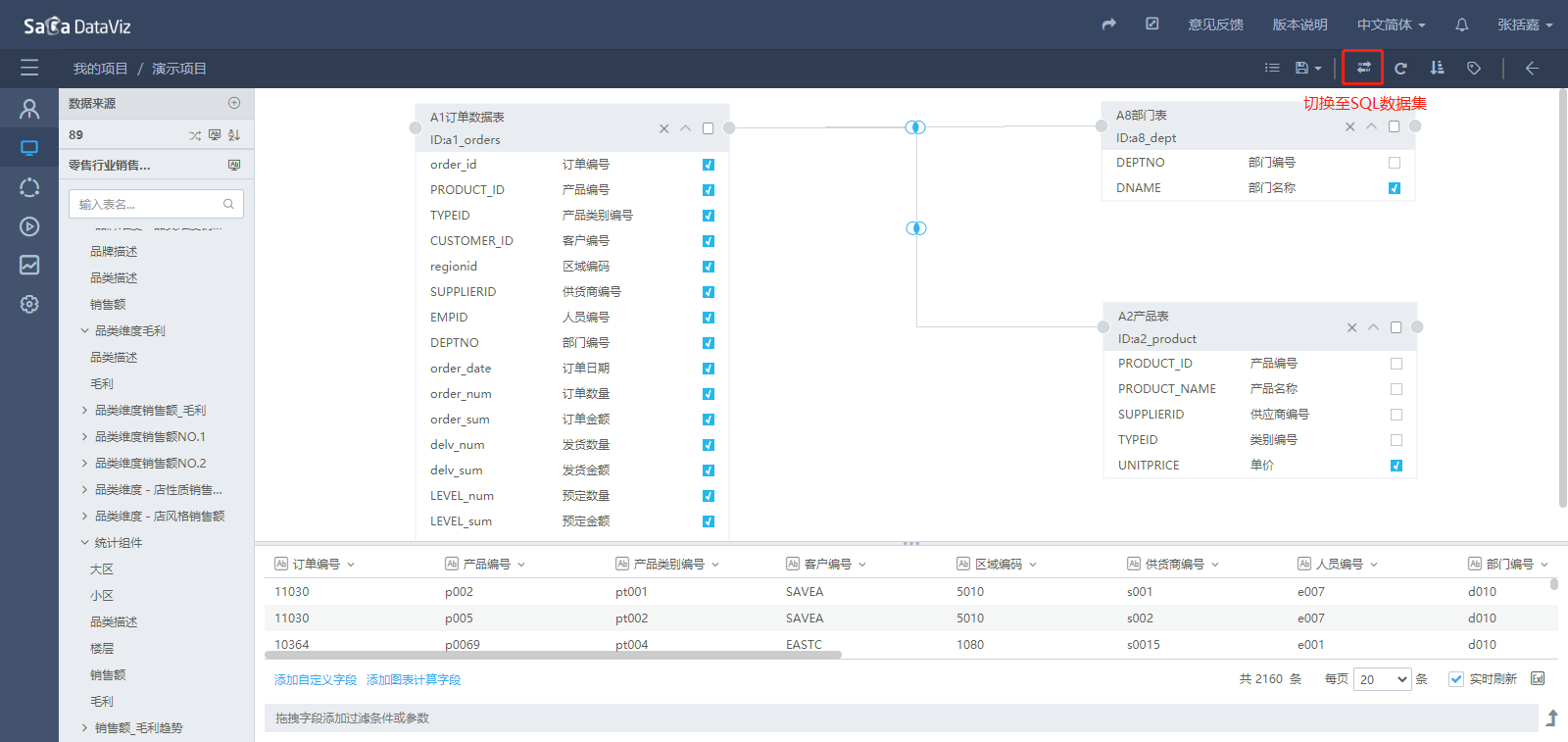
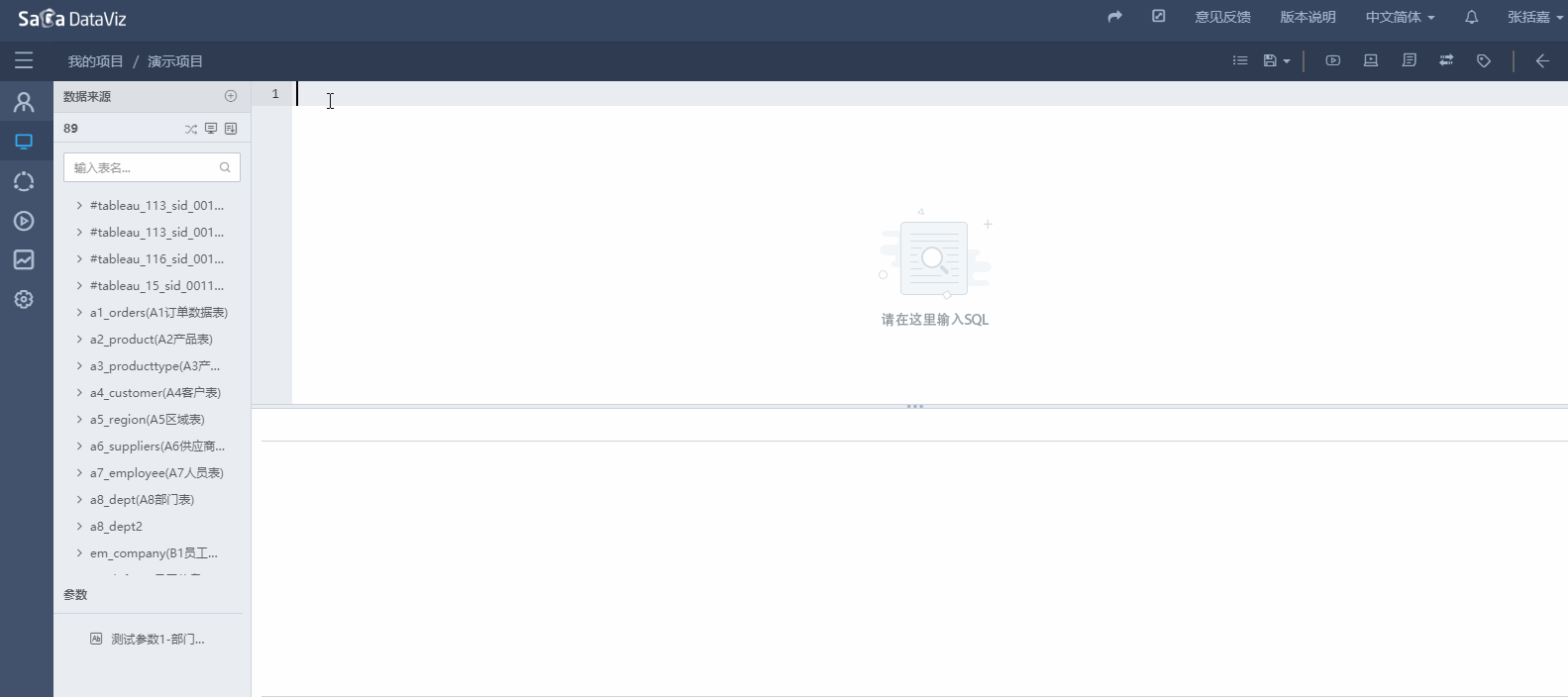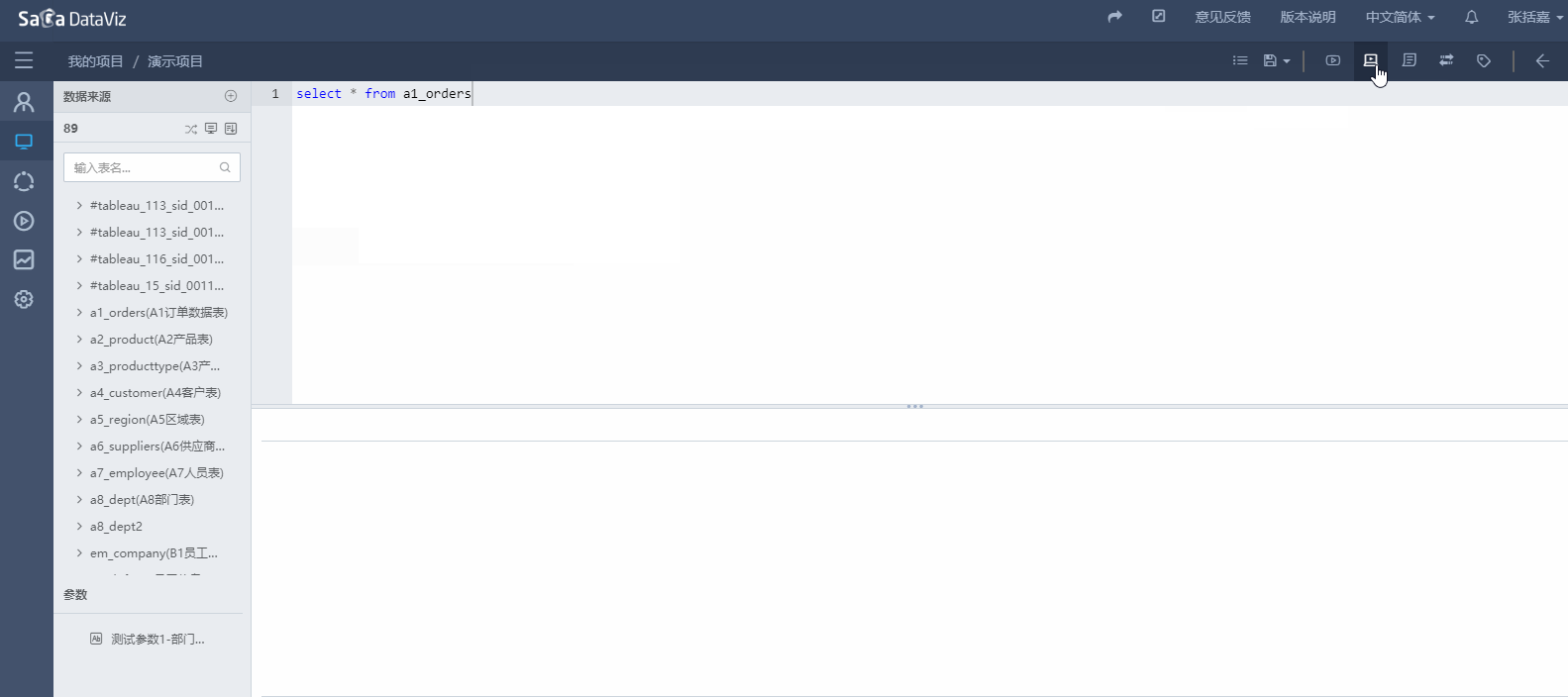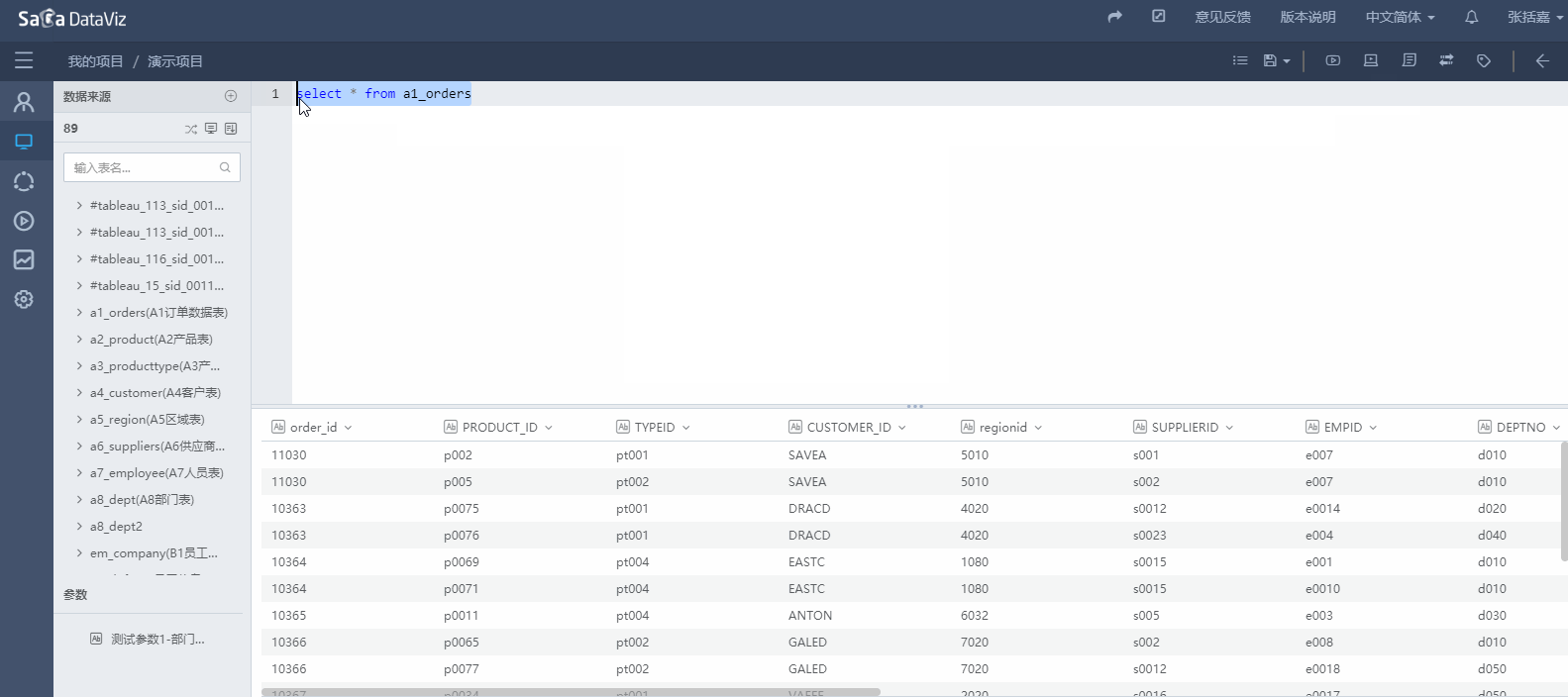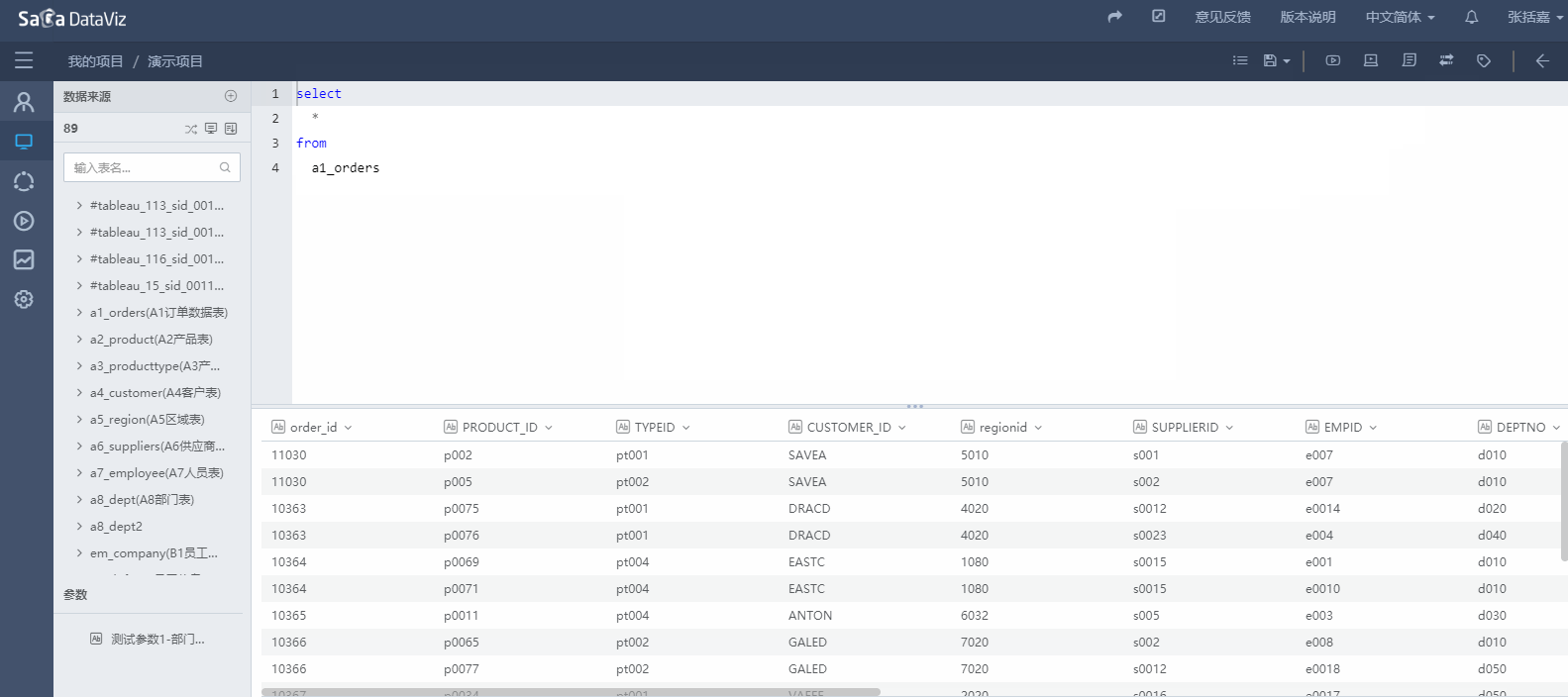
单击数据集界面上方的切换按钮即可切换到SQL数据集页面。如下图所示。
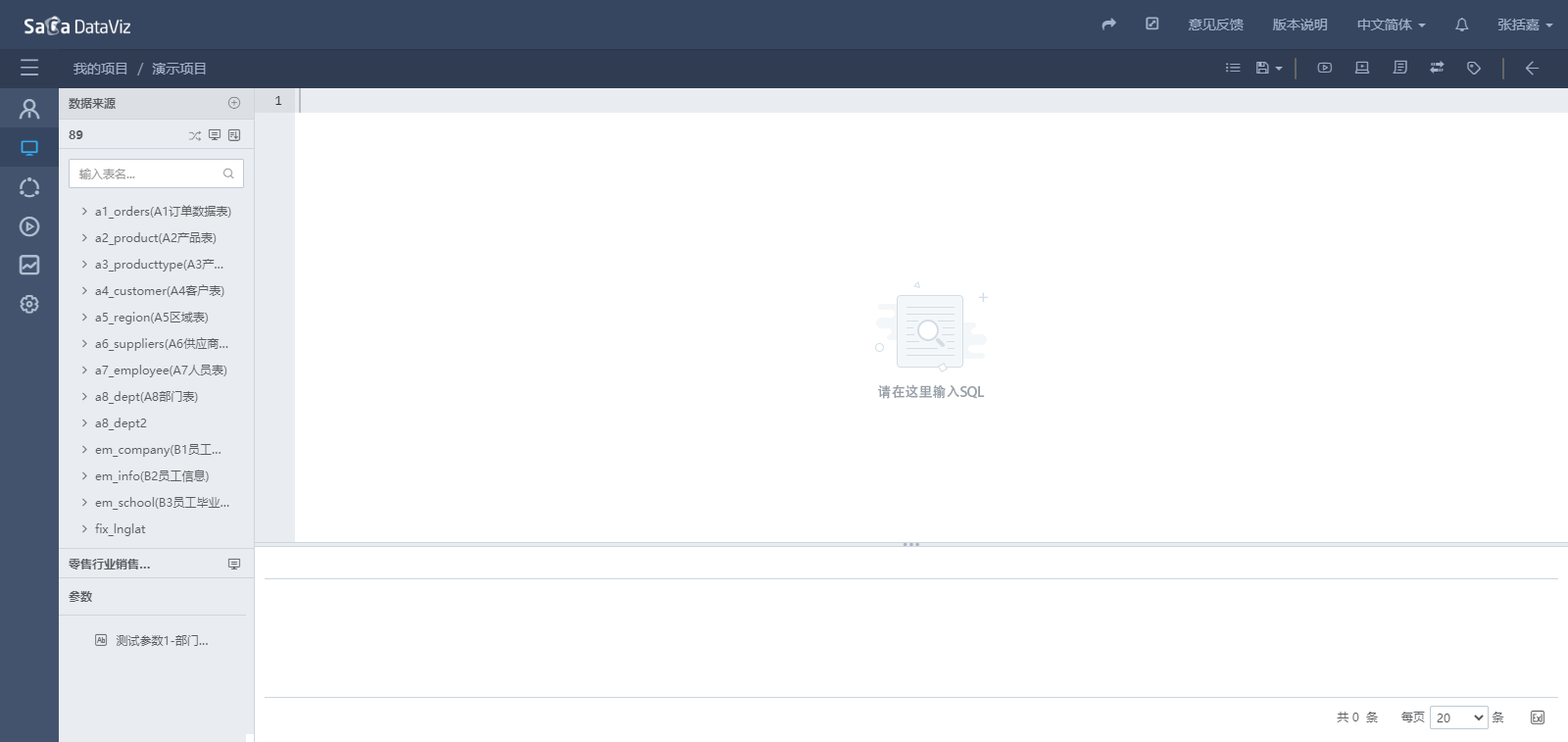
输入完SQL语句之后可以点击页面右上方执行按钮执行SQL,点击美化SQL按钮格式化SQL代码。如下图所示。
4.2.2.2.1 系统变量
可以在SQL中引用系统变量,写法与参数相同:${系统变量名},它们会依据系统变量的数据类型嵌入到实际的SQL中(列表型系统变量目前只能支持在 IN 断言中使用)。
select * from emp_table where id = ${uid}
select * from emp_table where org_id in ${orgids}
select * from emp_table where expire_date < ${now}
系统变量目前也支持另一种方括号写法:[系统变量显示名],该写法会替换方括号的内容为实际值,因此需要注意字符型及日期系统变量需要在外面添加单引号,列表型需要添加括号。该写法与表达式中的用法有一定差异,在后续版本中可能会取消支持。目前包含的系统变量有:[用户ID],[所属组织的用户ID],[所属组织及下属组织的用户ID],[所属组织ID],[所属组织及下属组织ID],[所属组织名称],[所属组织及下属组织名称]。
select * from emp_table where id= '[用户ID]';
select * from emp_table where org_id in ([所属组织ID]);
4.2.2.2.2 多数据源SQL
可以通过手写SQL执行查询做多数据源查询,只要在左侧存在多个数据源,书写的SQL便按照多数据源方式执行查询。此时有如下规则和限制:
- 同一数据集中不能同时使用具有相同名称的数据源。
- SQL中所有的表引用(主要出现于SELECT 的 FROM子句),除了可能需要的Schema、Catalog、表名外,需要额外添加数据源名前缀,且要求此时数据源名、Catalog(如果有)、Schema(如果有)每项必须使用双引号作为分隔标识符括起来(表名不要求),标识符与表引用使用的点之间不能包含空格或换行。支持的写法如:
"数据源A"."TableA","数据源B"."SchemaA".TableA,不支持的写法如:"数据源B".SchemaA.TableA,"数据源A" . "TableA"。 - SQL中的列引用中指定表名时,应使用 FROM 子句中的定义别名,而不是重复书写原始表名。例如:
select t1.colA from "DS1"."Schema1".Table t1。 - SQL语法使用类SQL-1992标准SQL的语法(使用双引号作为分隔标识符),不支持原始数据源的数据库函数,只支持特定的函数。
- 由于一些技术限制,取决于原始数据源对SQL特性的支持情况及SQL的某些写法,某些符合语法结构的SQL也有可能出现无法执行的情况。最保守的情况下只能使用原始数据库支持的SQL特性。
- 多数据源SQL与多数据源拖拽一样,相较单数据源会需要更多的服务器内存及CPU资源。
4.2.2.2.2.1 多数据源 SQL 支持的语法结构
多数据源SQL目前支持如下常见的标准SELECT中的语法结构(非完全列举)。
- WITH(CTE)
- UNION
- INTERSECT
- LIMIT start, offset
- INNER/LEFT/RIGHT/FULL JOIN ON
- DATE、TIME、TIMESTAMP 常量
4.2.2.2.2.2 多数据源 SQL 支持的运算符及函数
4.2.2.2.2.2.1 比较运算符
- value1 = value2
- value1 <> value2
- value1 != value2
- value1 > value2
- value1 >= value2
- value1 < value2
- value1 <= value2
- value IS NULL
- value IS NOT NULL
- value1 BETWEEN value2 AND value3
- value1 NOT BETWEEN value2 AND value3
- string1 LIKE string2 [ ESCAPE string3 ]
- string1 NOT LIKE string2 [ ESCAPE string3 ]
- value IN (value [, value]*)
- value NOT IN (value [, value]*)
- value IN (sub-query)
- value NOT IN (sub-query)
- value comparison SOME (sub-query)
- value comparison ANY (sub-query)
- value comparison ALL (sub-query)
- EXISTS (sub-query)
4.2.2.2.2.2.2 逻辑运算符
- boolean1 OR boolean2
- boolean1 AND boolean2
- NOT boolean
4.2.2.2.2.2.3 算术运算符
- + numeric
- - numeric
- numeric1 + numeric2
- numeric1 - numeric2
- numeric1 * numeric2
- numeric1 / numeric2
- numeric1 % numeric2
4.2.2.2.2.2.4 条件运算符
CASE value WHEN value1 [, value11 ]* THEN result1 [ WHEN valueN [, valueN1 ]* THEN resultN ]* [ ELSE resultZ ] END
CASE WHEN condition1 THEN result1 [ WHEN conditionN THEN resultN ]* [ ELSE resultZ ] END
4.2.2.2.2.2.5 类型转换
- CAST(value AS type)
4.2.2.2.2.2.6 数学函数
- POWER(numeric1, numeric2)
- ABS(numeric)
- MOD(numeric1, numeric2)
- SQRT(numeric)
- LN(numeric)
- LOG10(numeric)
- EXP(numeric)
- CEIL(numeric)
- FLOOR(numeric)
- ACOS(numeric)
- ASIN(numeric)
- ATAN(numeric)
- ATAN2(numeric, numeric)
- COS(numeric)
- COT(numeric)
- DEGREES(numeric)
- PI()
- RADIANS(numeric)
- ROUND(numeric1 [, numeric2])
- SIGN(numeric)
- SIN(numeric)
- TAN(numeric)
4.2.2.2.2.2.7 字符函数
- string || string
- CHAR_LENGTH(string)
- UPPER(string)
- LOWER(string)
- POSITION(string1 IN string2)
- TRIM( { BOTH | LEADING | TRAILING } string1 FROM string2)
- OVERLAY(string1 PLACING string2 FROM position [ FOR length ])
- SUBSTRING(string FROM position)
- SUBSTRING(string FROM position FOR length)
4.2.2.2.2.2.8 时间日期函数
LOCALTIME
LOCALTIMESTAMP
CURRENT_TIME
CURRENT_DATE
CURRENT_TIMESTAMP
EXTRACT(timeUnit FROM datetime)
FLOOR(datetime TO timeUnit)
CEIL(datetime TO timeUnit)
YEAR(date)
QUARTER(date)
MONTH(date)
WEEK(date)
DAYOFYEAR(date)
DAYOFMONTH(date)
DAYOFWEEK(date)
HOUR(date)
MINUTE(date)
SECOND(date)
TIMESTAMPADD(timeUnit, integer, datetime)
TIMESTAMPDIFF(timeUnit, datetime, datetime2)
其中时间单位 timeUnit 可取值为:
YEAR,MONTH,WEEK,DAY,HOUR,MINUTE,SECOND。
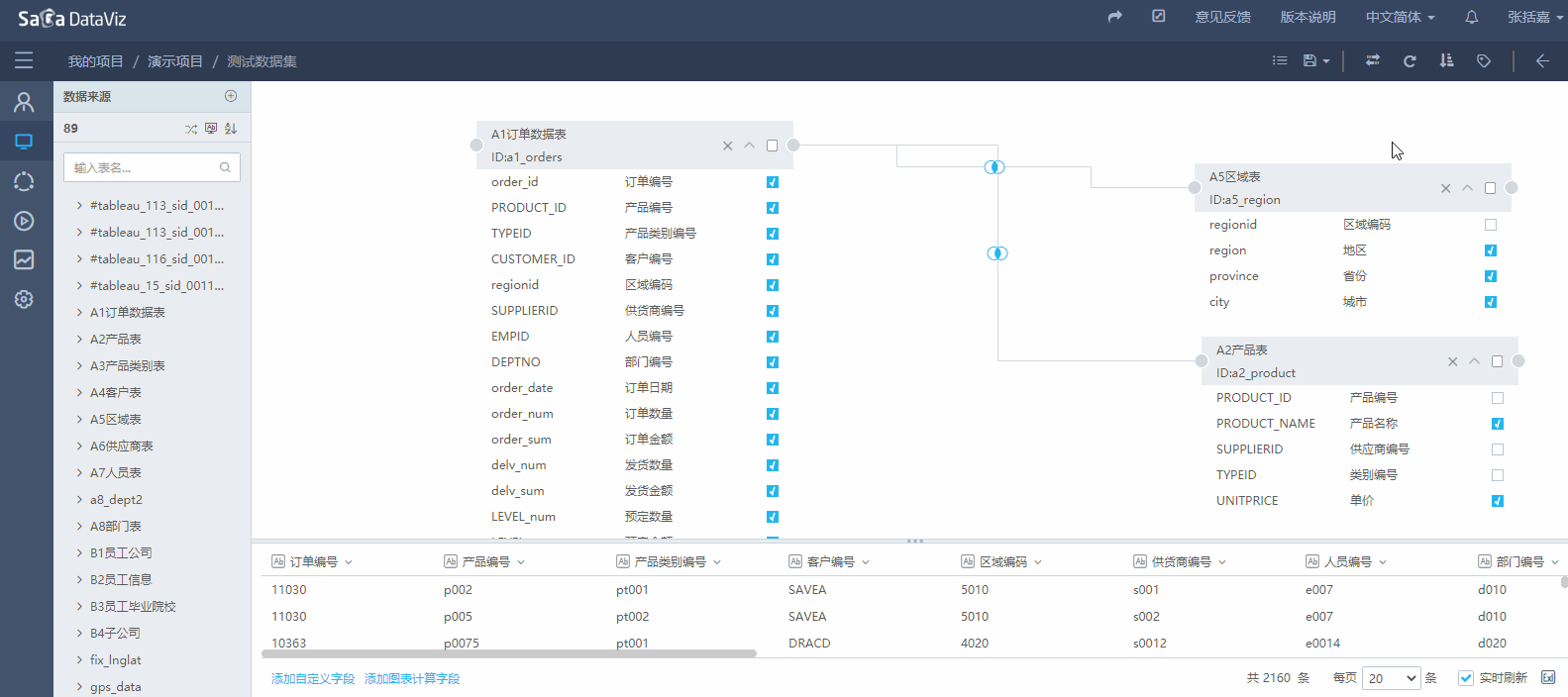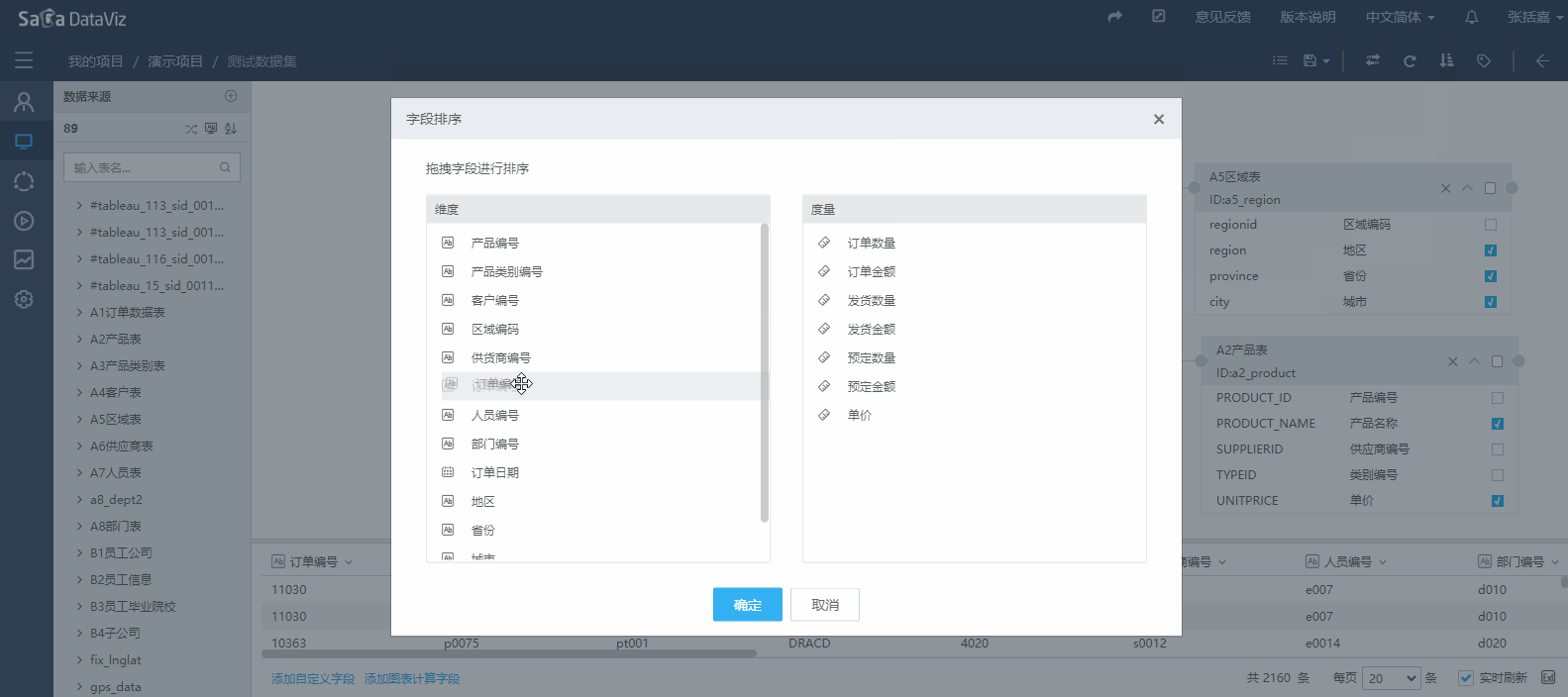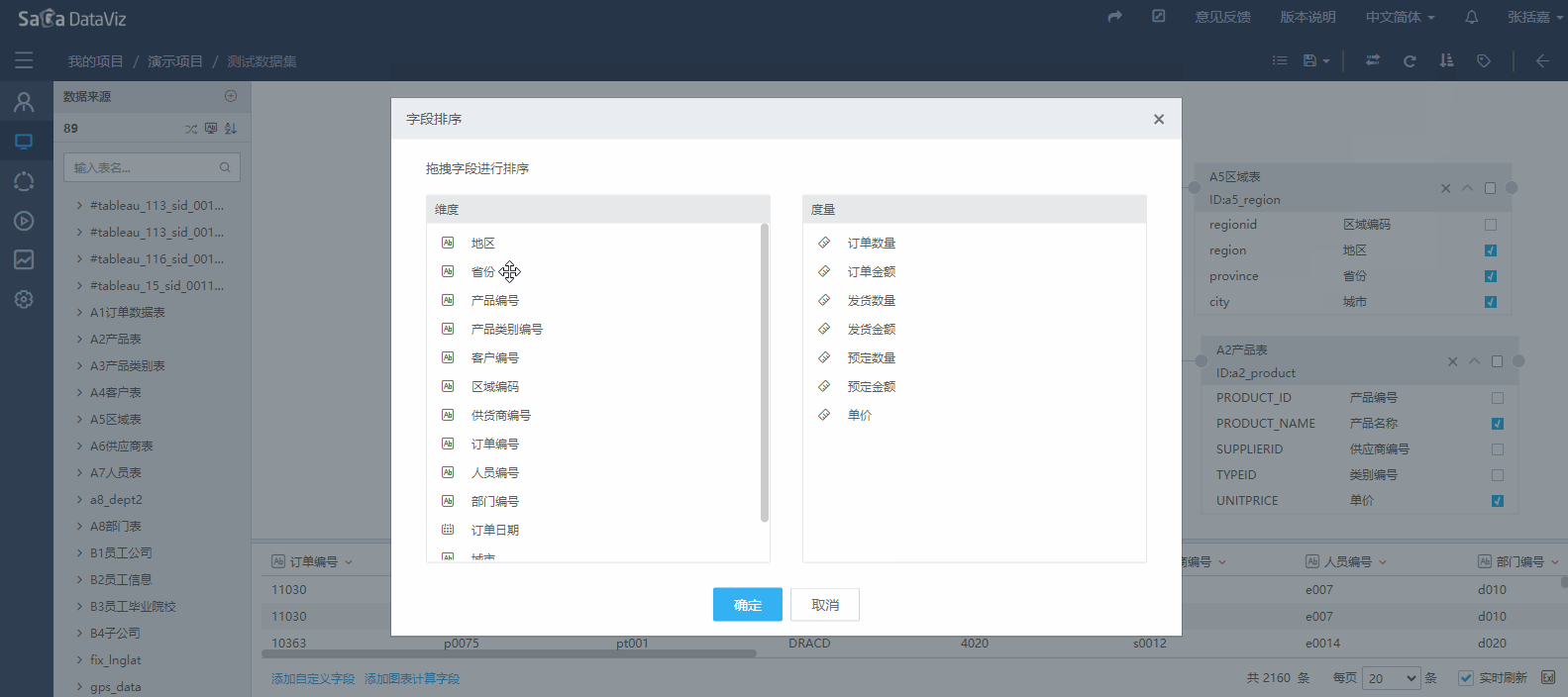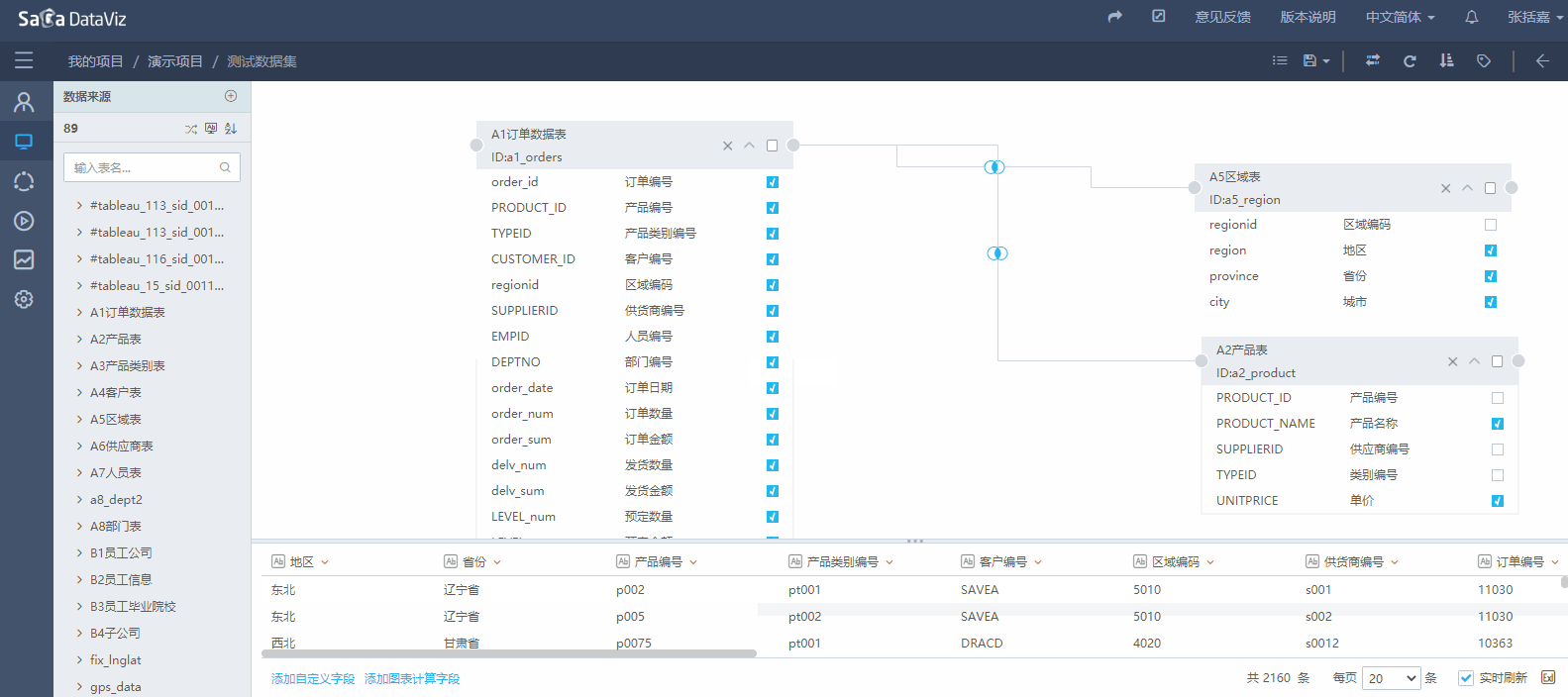
4.2.2.3 数据集字段排序
如果希望在数据集的字段在之后的编辑图表时可以按照指定的顺序显示,需要先设定数据集字段的顺序。如下图:
4.2.2.4 标签
标签用于组织数据集,当创建的数据集数量非常多时,使用标签检索数据集会非常高效。单击页面右上角标签按键,在弹出页面可以编辑标签,也可以对数据集打标签。一个数据集可以添加多个标签。(V5.5.06版本之后新增前台删除标签功能)
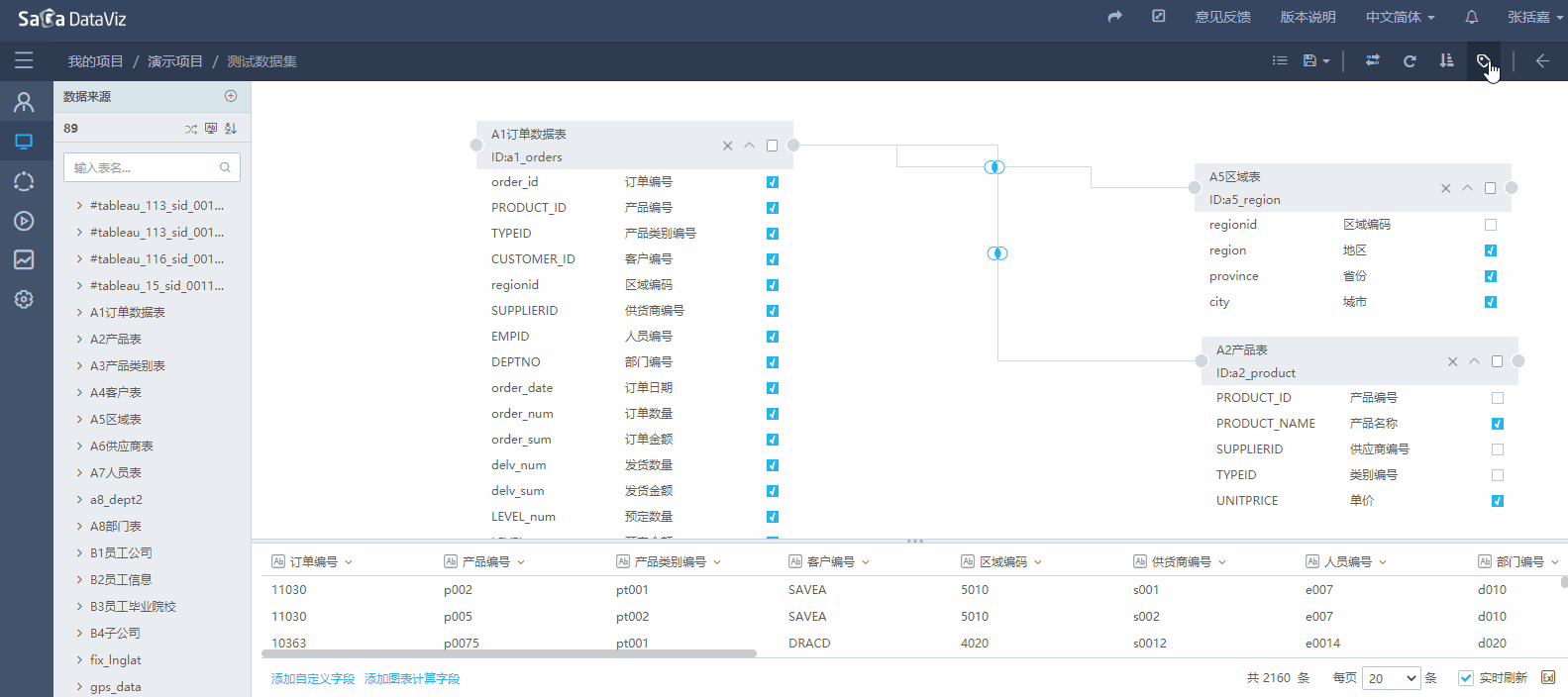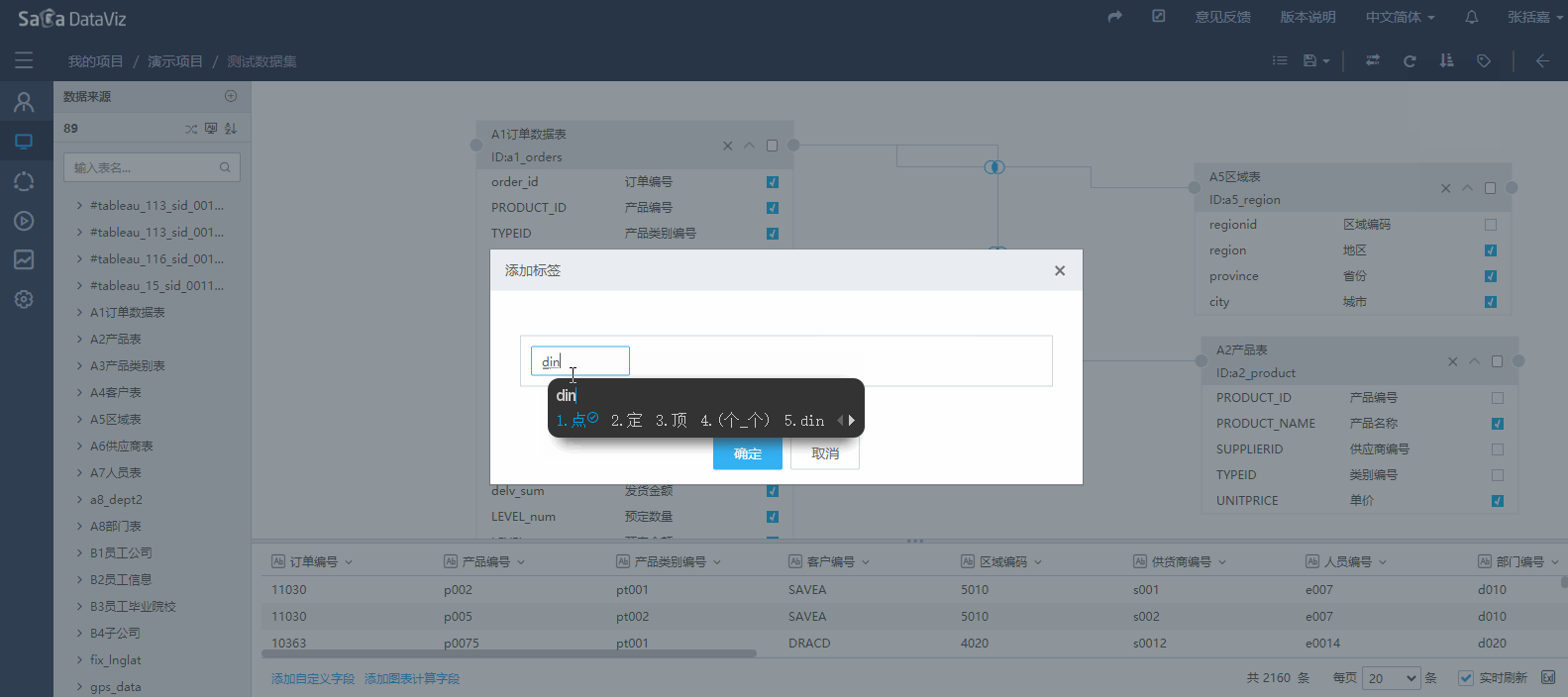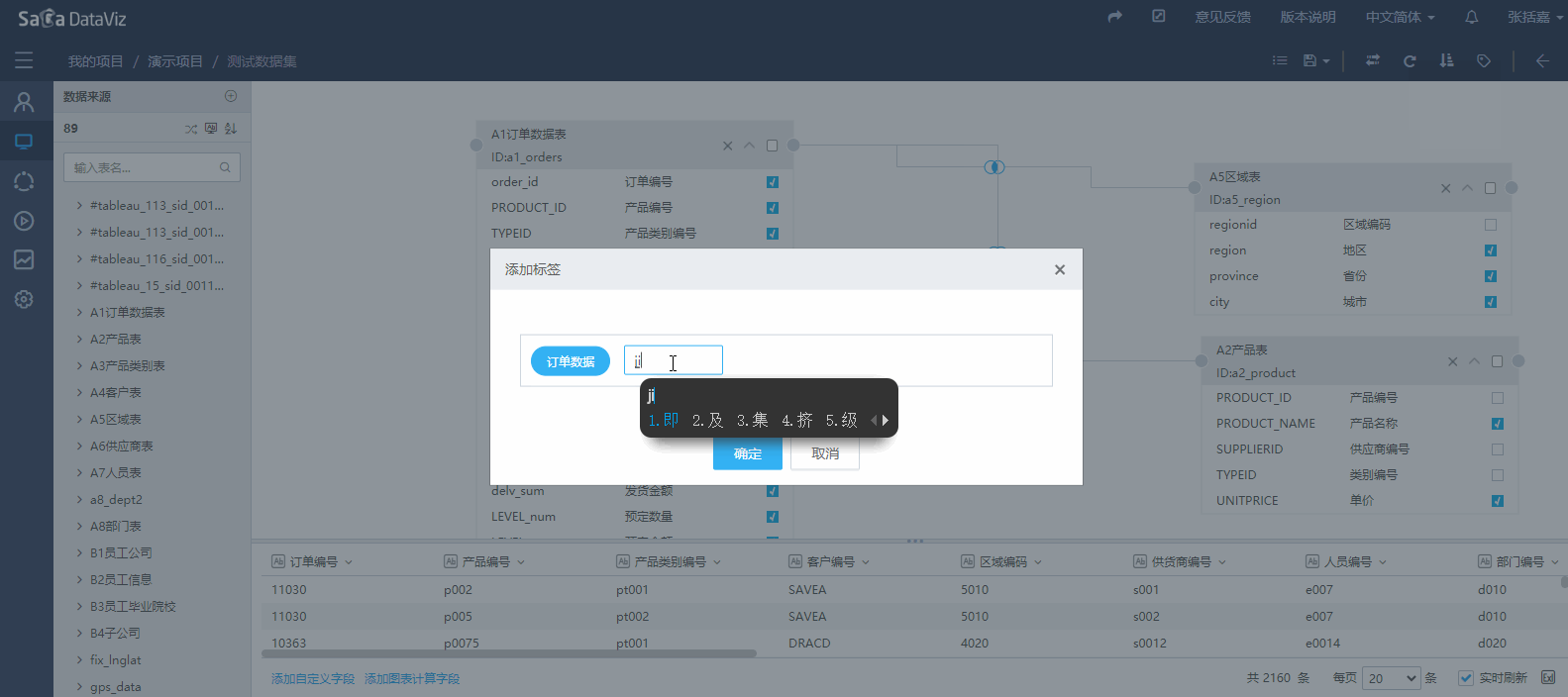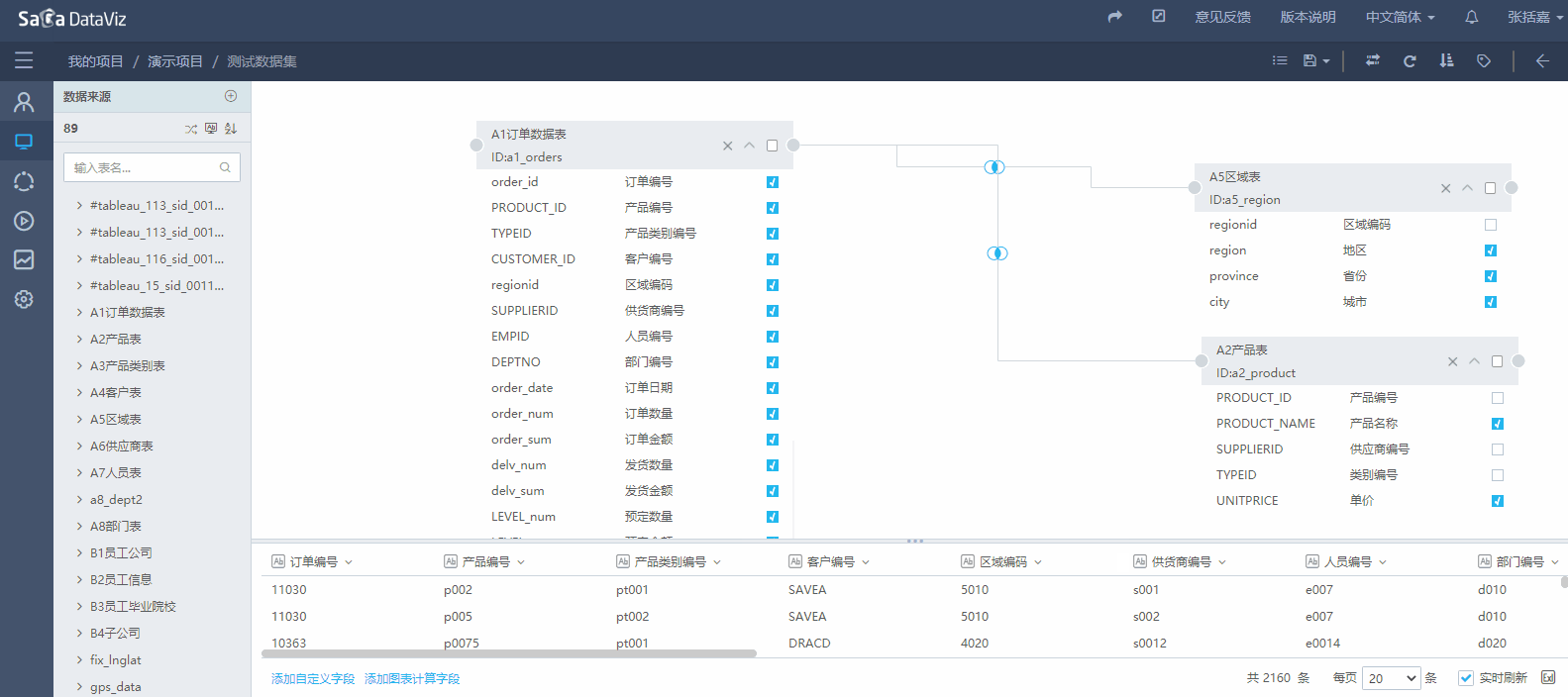
4.2.2.5 字符类型字段排序
字符类型字段排序作用于项目全局,后续依赖此“数据集”的“图表”、“图册”及“字符类型过滤条件列表”的排序均默认以此顺序为准。但是此顺序在数据集预览中并不会体现。
点击字段下拉菜单中的“排序”按钮,弹出“自定义排序”页面,在该页面可以选择“默认排序”、“字母/拼音排序”、“其他字段”、“手动排序”等排序方式。如下图:
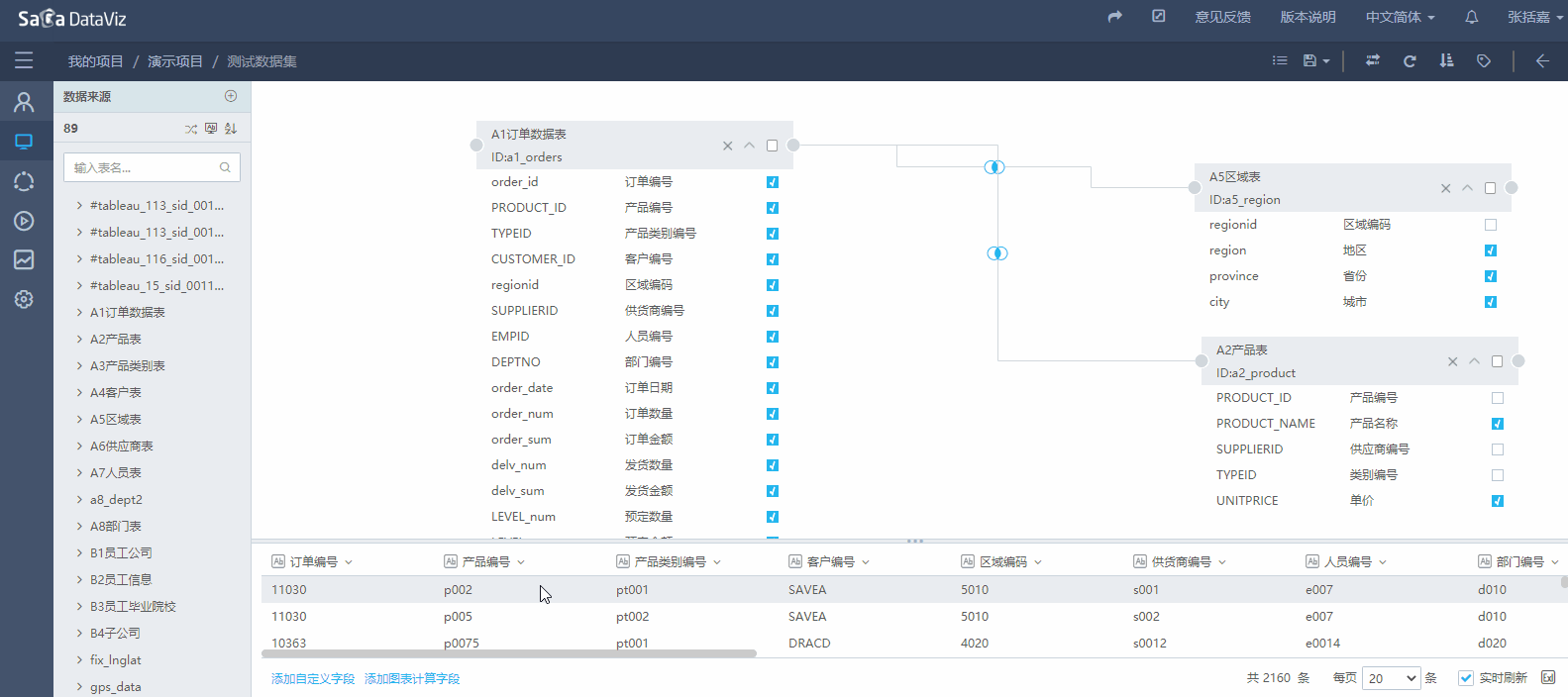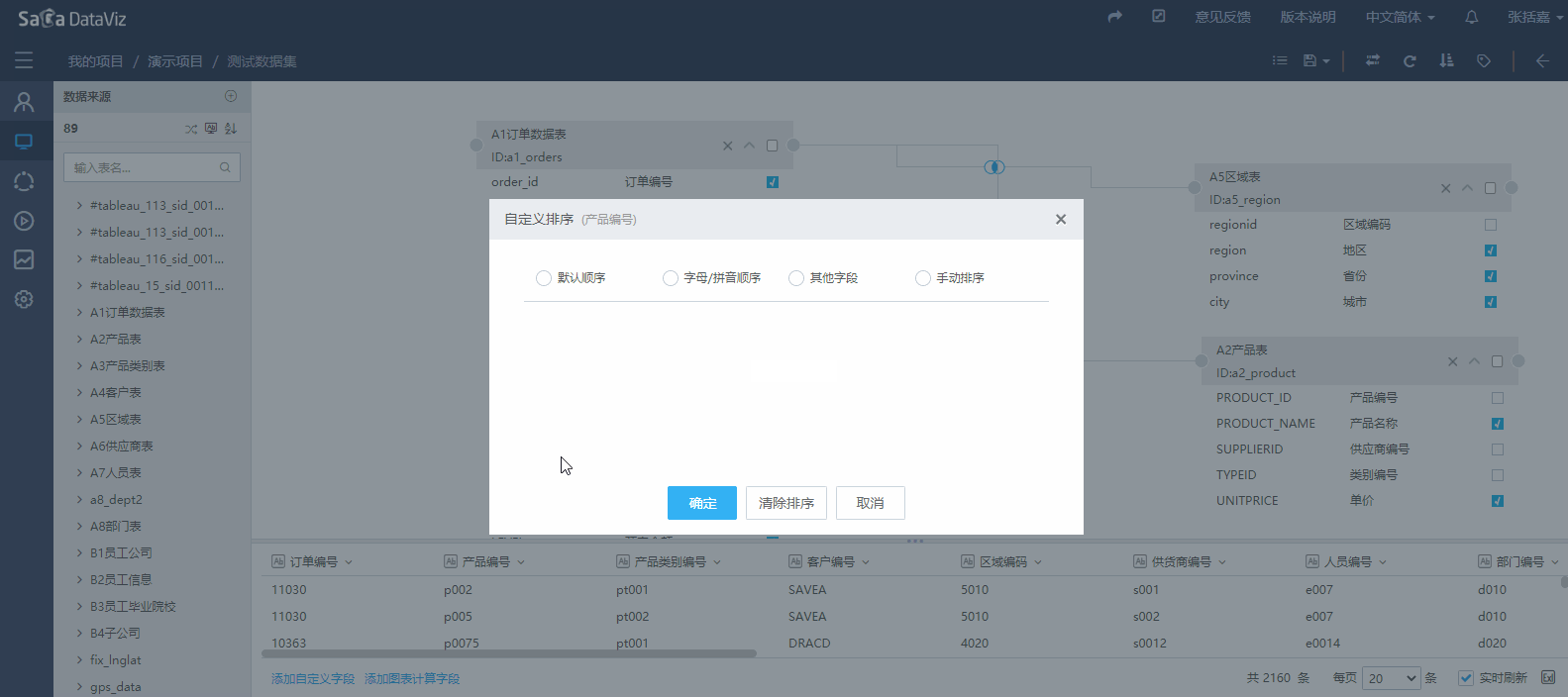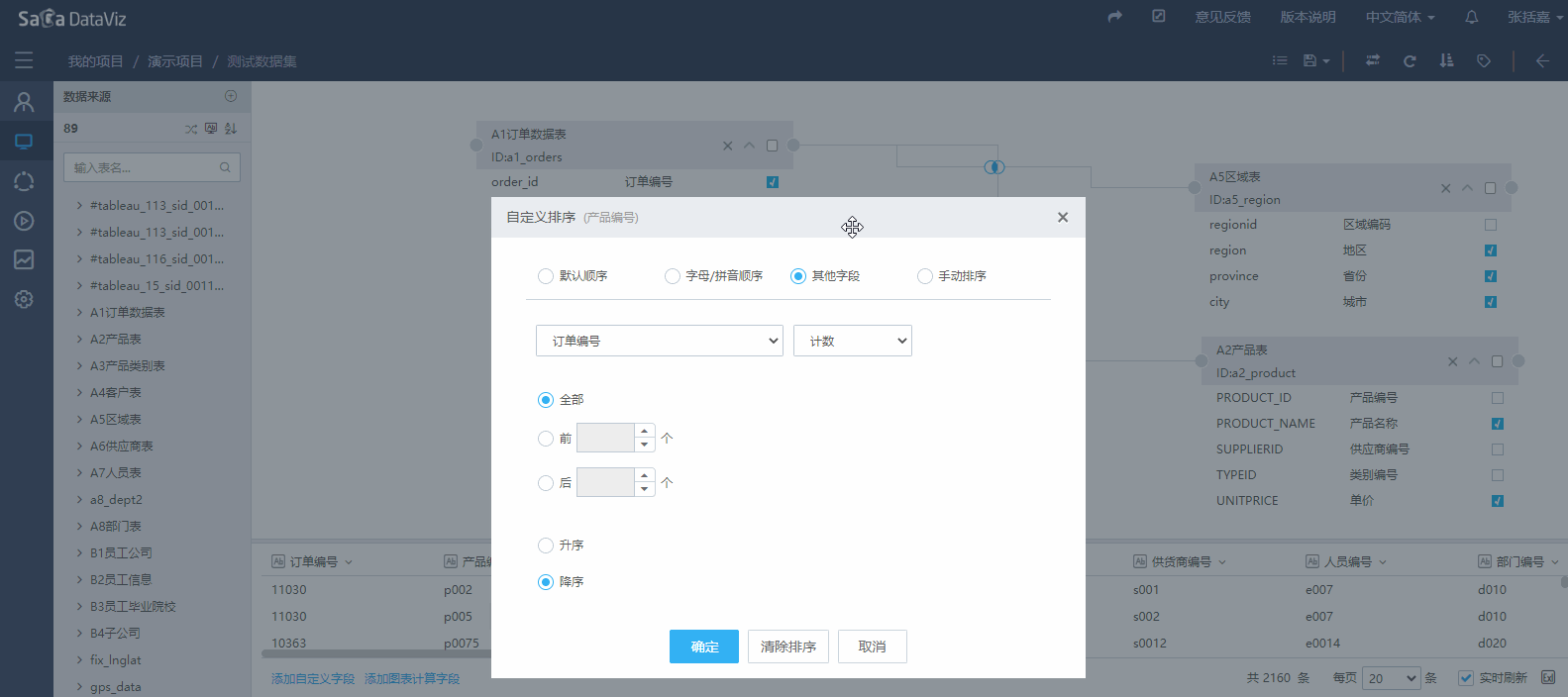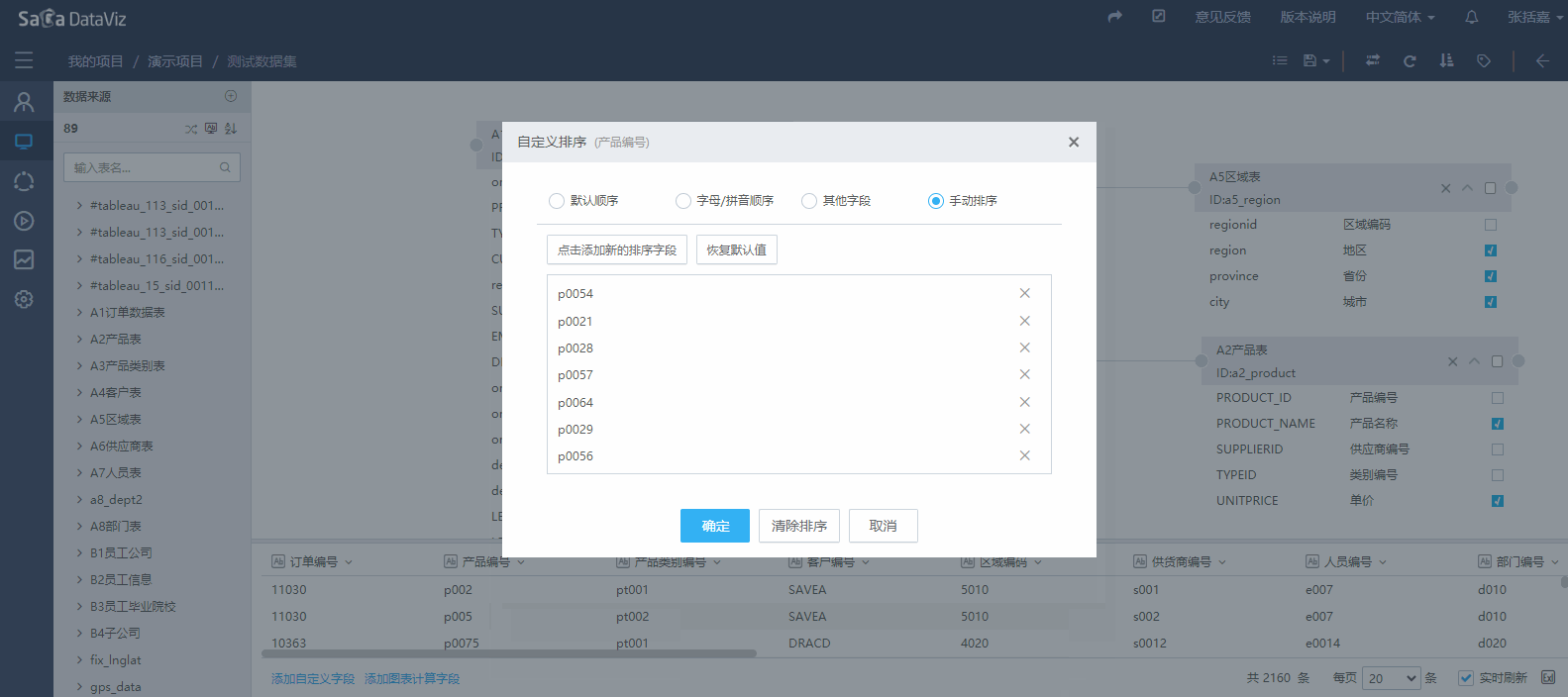
这里“其他字段”选项指的是以数据集中另一个字段作为排序依据。(典型应用:用户名单中有用户序号字段,那么就可以根据序号字段对用户姓名进行排序)
4.2.2.6 详细信息设置
点击字段下拉菜单中的“详细信息设置”按钮,弹出“详细信息设置”页面,在其中可以选择是否在图表的详细信息项中显示该字段(默认勾选),以及设置详细信息跳转页面(默认不勾选)。如下图所示,为“订单编号”字段设置跳转页面,取消“产品编号”字段在详细信息项中的显示:
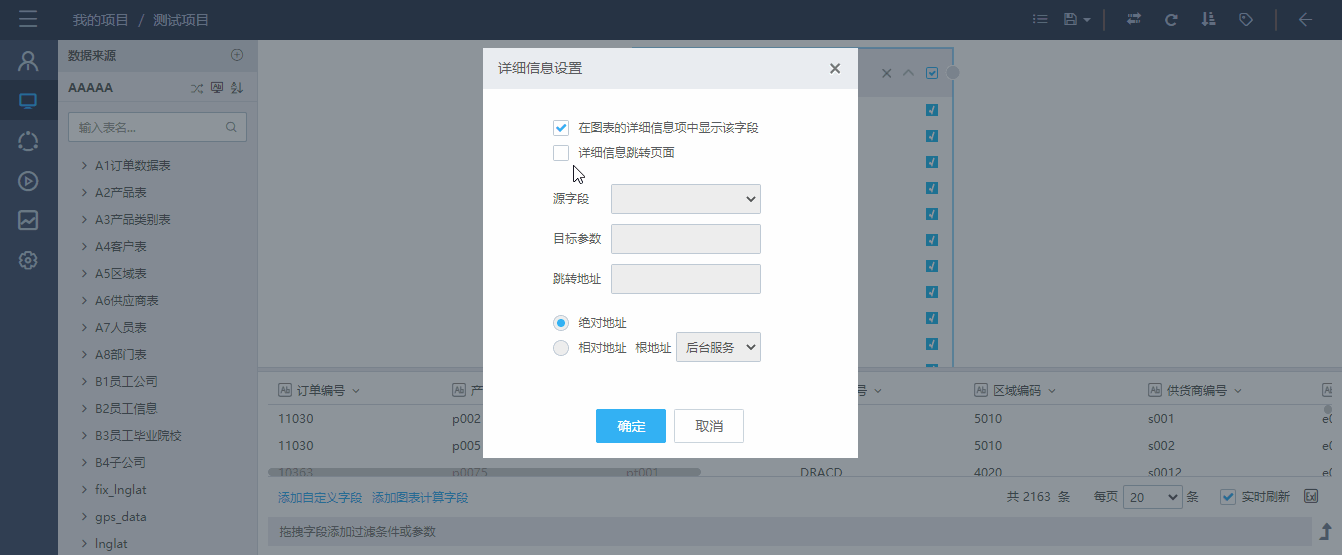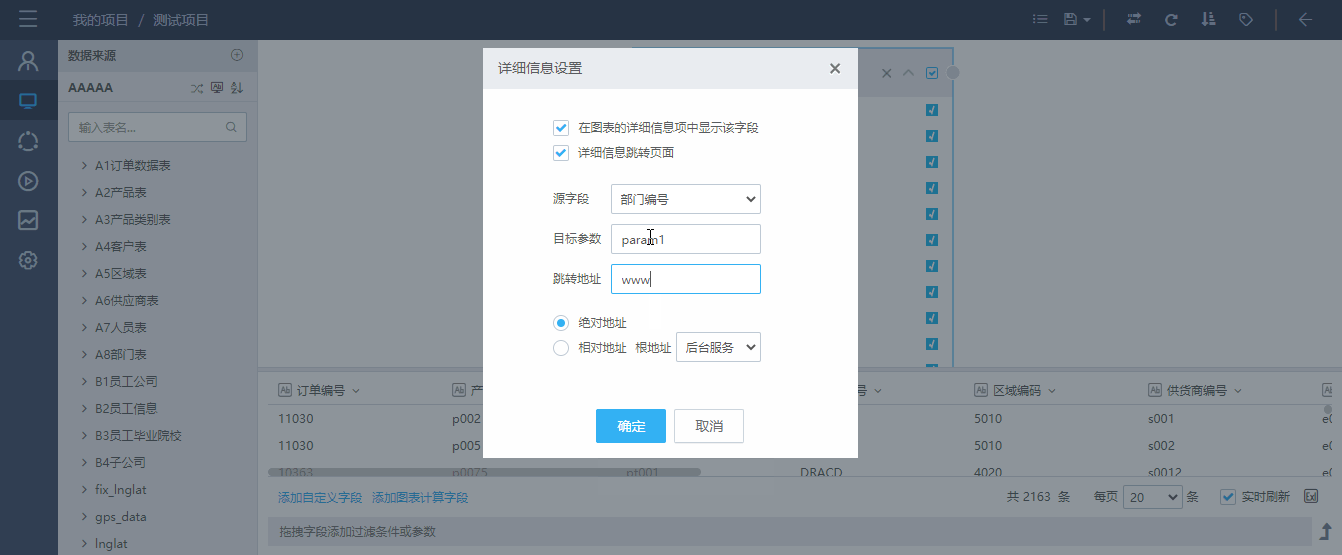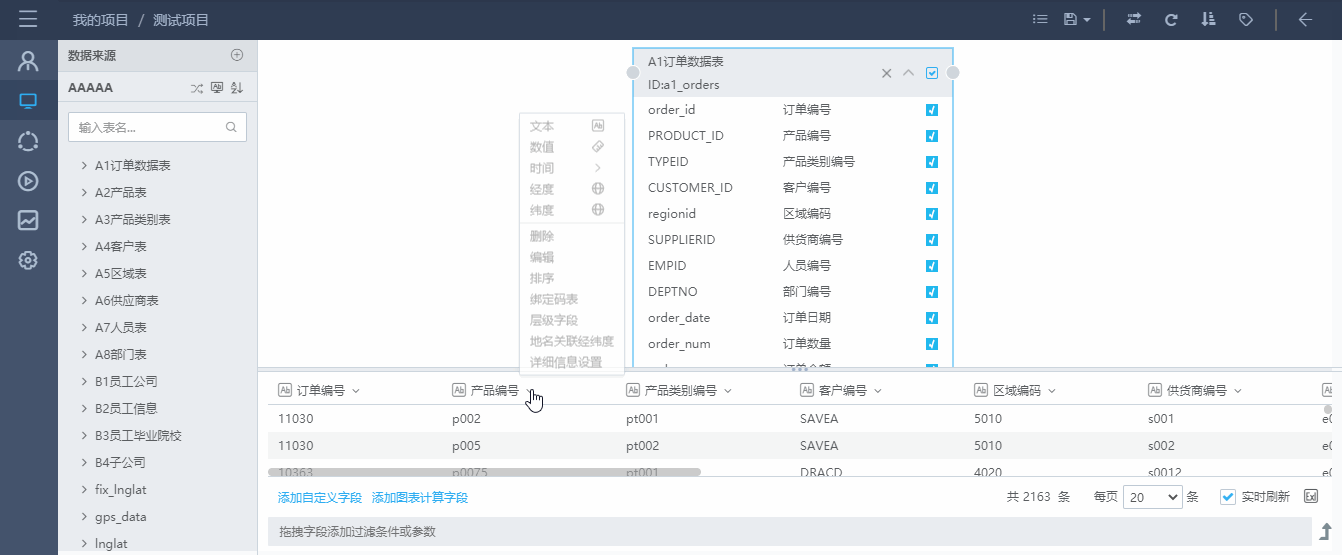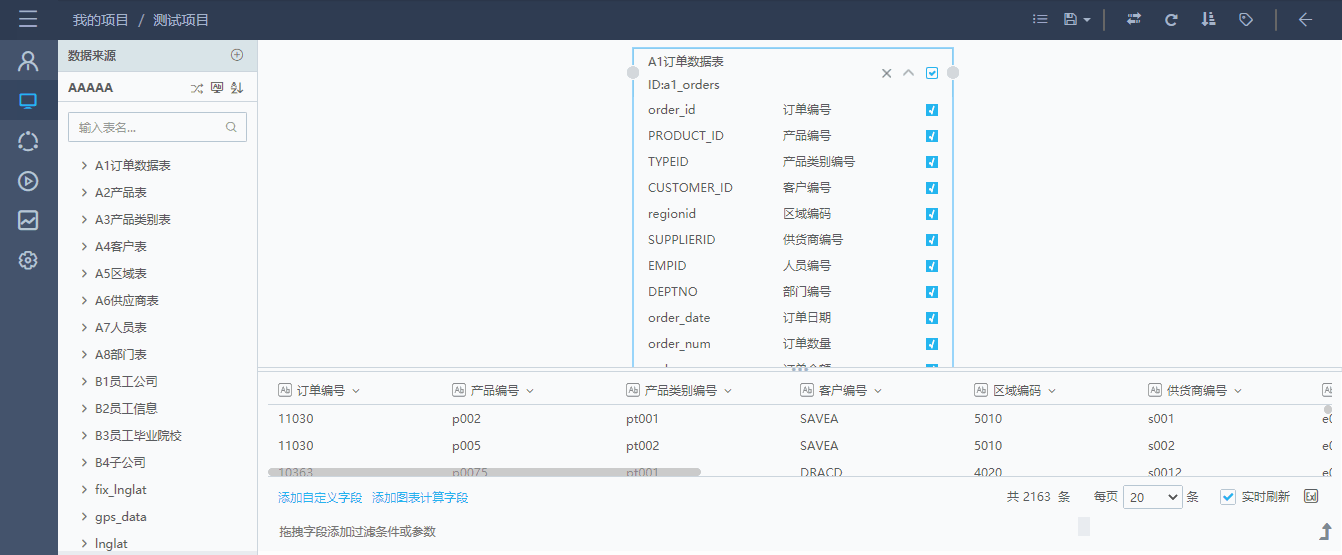
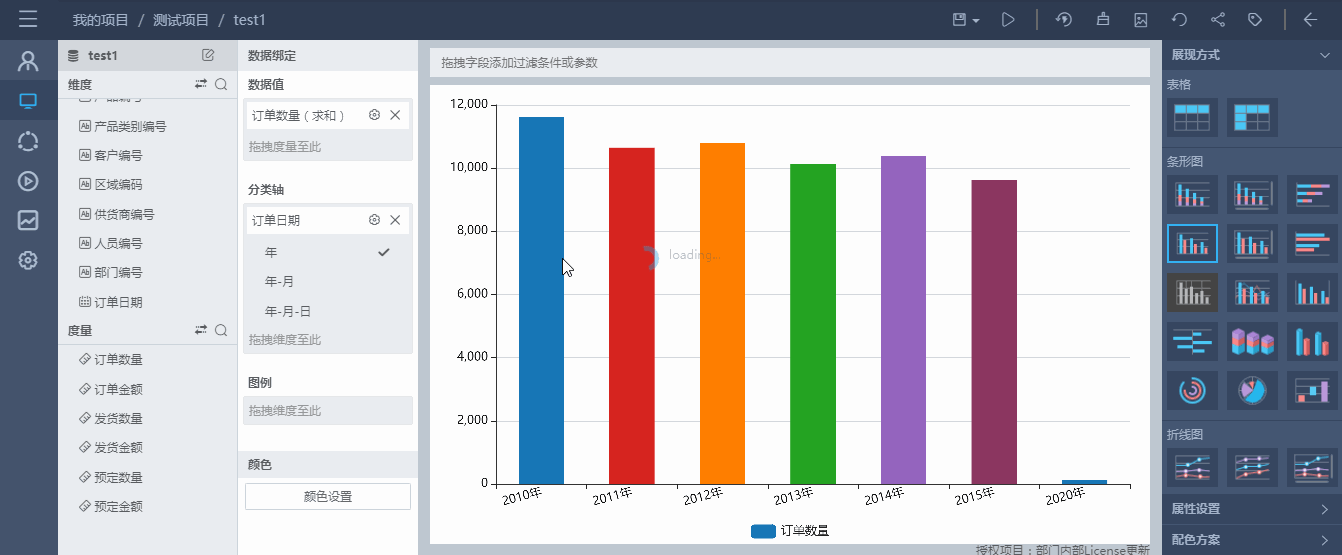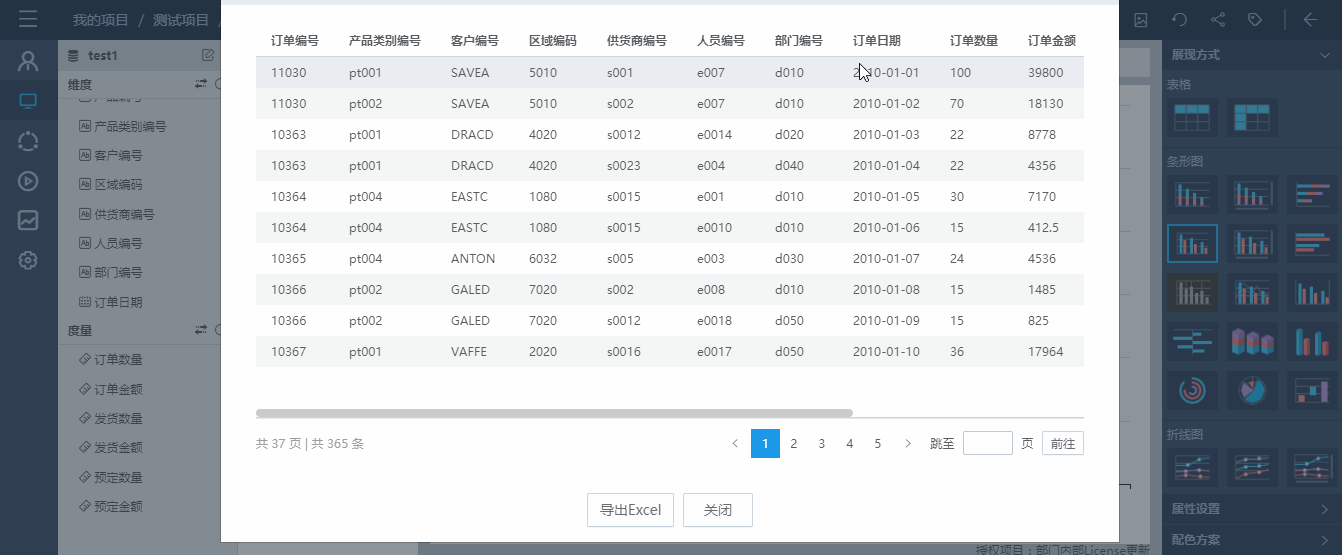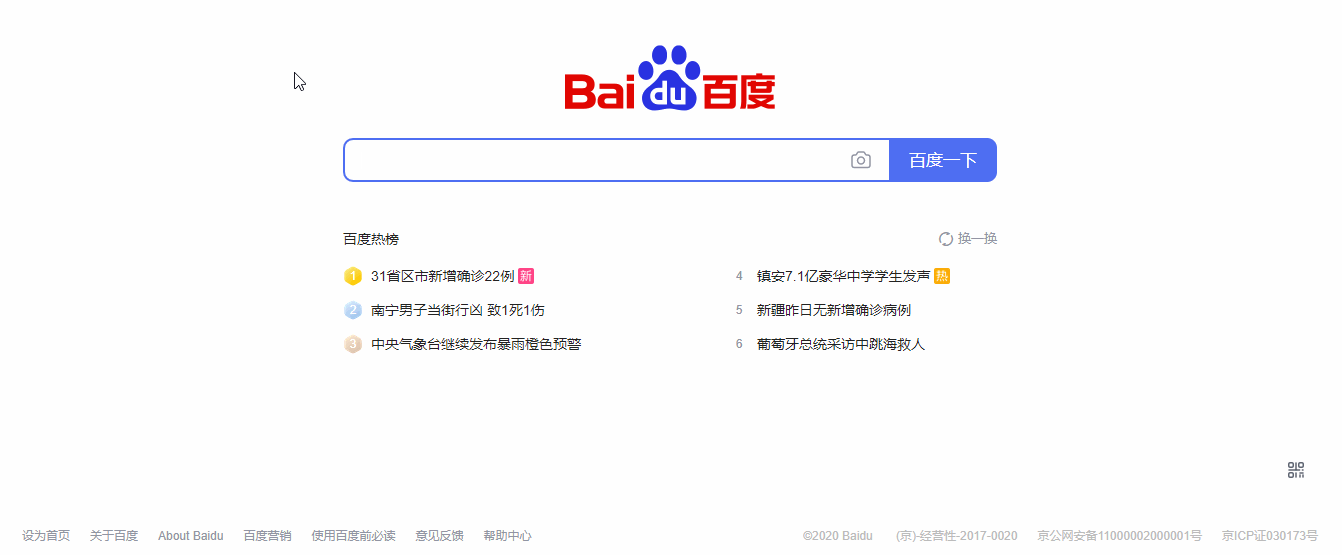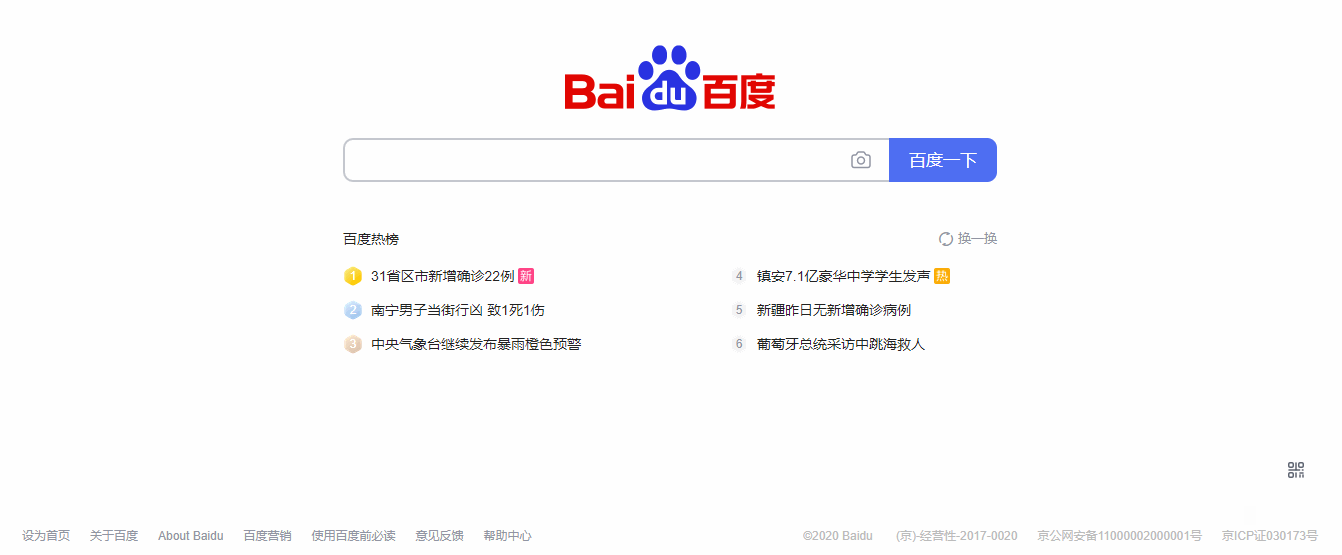
在图表页面右键点击“详细信息项”按钮后,选择了“否”的字段(“产品编号”)的数据内容没有被显示出来,在设置了跳转地址的字段(“订单编号”)上点击,即可跳转至指定页面,并以url参数的形式,将指定字段的值传递至目标页面。如下图所示。
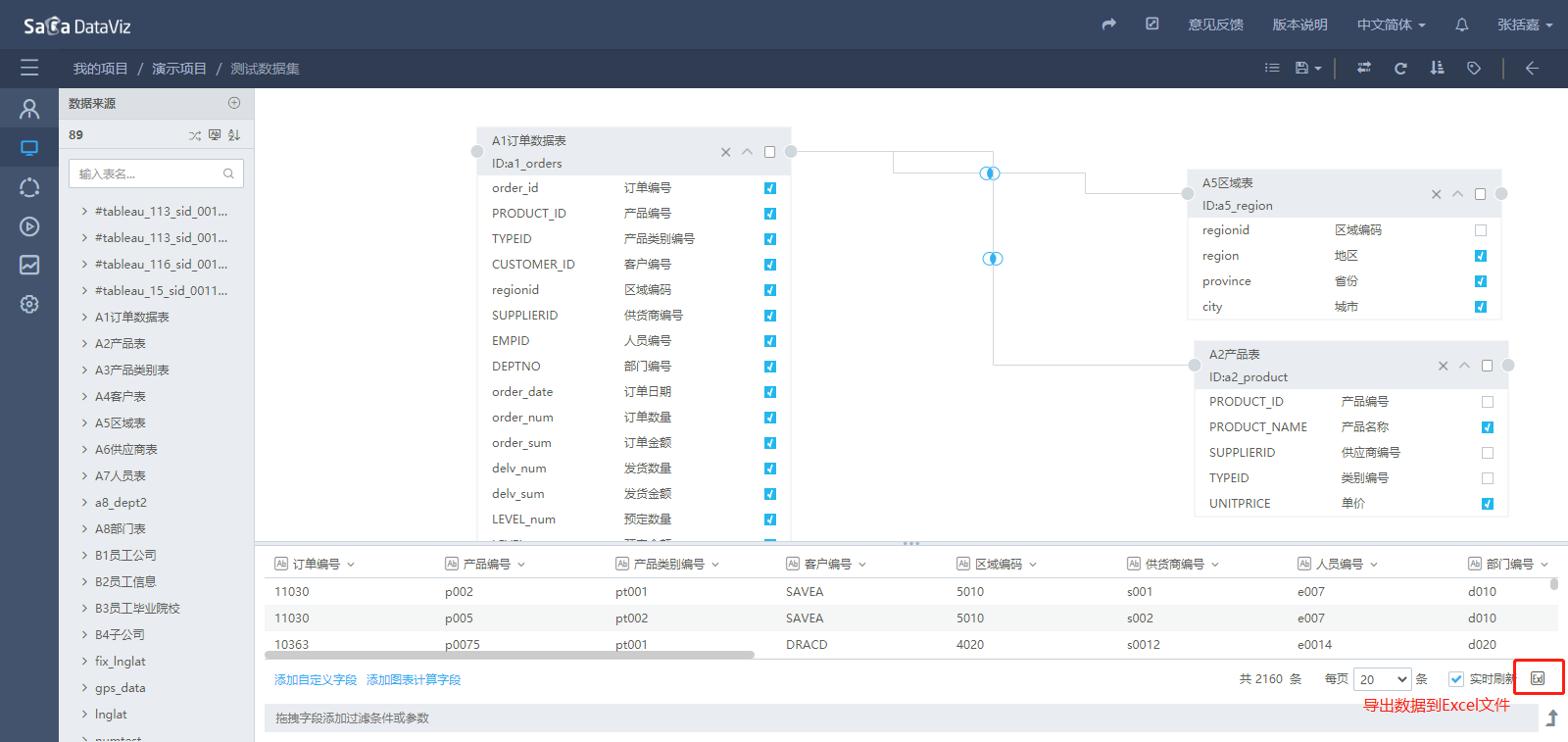
4.2.2.7 导出Excel
点击数据集字段预览区域的导出按钮,可以把数据集中的数据导出到Excel中。如下图所示。
4.2.2.8 保存数据集
保存数据集有如下几种方法:
1. 点击右上角保存按钮,可以把数据集模型存储到数据库中。
2. 点击保存按钮右侧的小箭头,弹出下拉菜单,选择重命名,可以保存数据集并修改当前数据集的名称。
3. 点击保存按钮右侧的小箭头,弹出下拉菜单,选择另存为,可以把当前数据集另存为一个新的数据集。
4. 点击保存按钮右侧的小箭头,弹出下拉菜单,选择保存并新增,可以把当前数据集保存到数据库中并且清空数据集编辑区域以便继续创建其他数据集。
4.2.2.9 添加大数据计算引擎
此功能的详细说明请参考最佳实践:《高性能分析引擎》
4.2.3 编辑数据集
在项目资源页面,点击一个数据集进入数据集定义页面,可以进行数据集的编辑。
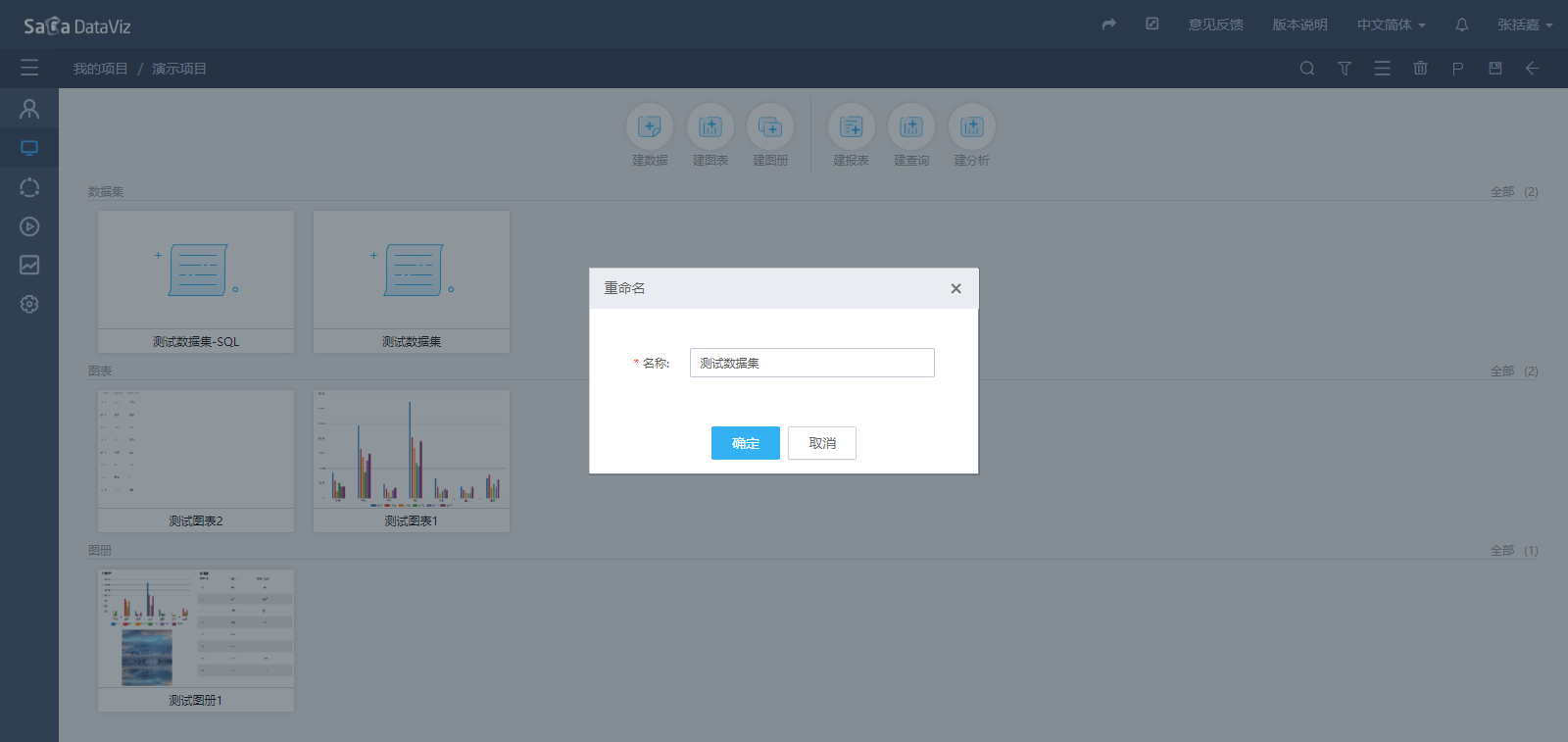
4.2.4 重命名数据集
在项目资源页面,将鼠标悬浮在数据集上,点击数据集右上角的重命名按钮,在弹出窗口中修改数据集的名称。如下图所示。
4.2.5 删除数据集
删除数据集有两种方式:
单个删除:将鼠标悬浮在数据集上,点击数据集右上角的删除按钮,删除单个数据集。
批量删除:在项目资源页面中,点击页面右上角的批量删除按钮,选中要删除的数据集,然后点击页面下的删除按钮进行批量删除。
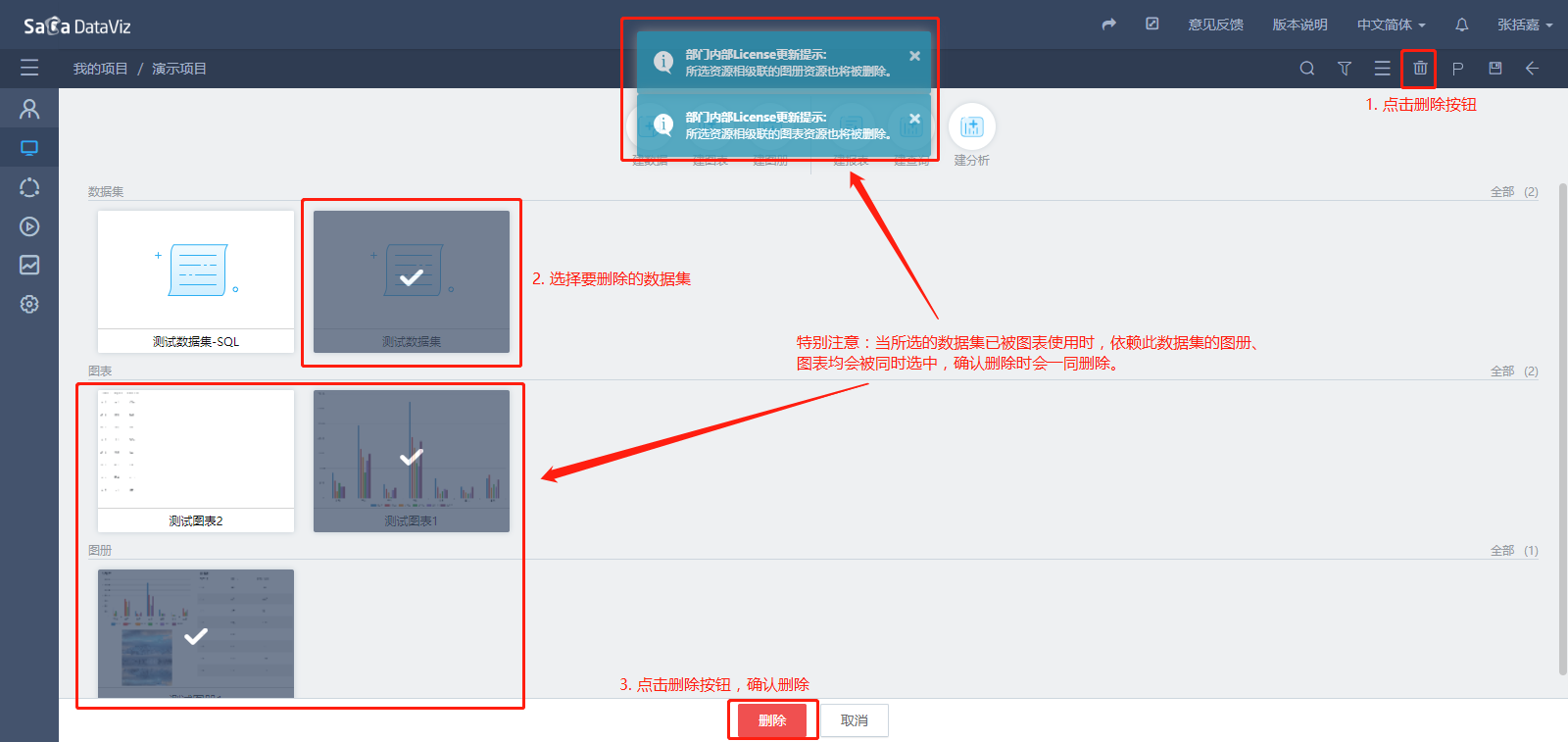
【注意】当选择的数据集被图表使用时依赖此数据集的图表和图册都会被选中,点击删除时会被一起删除。
4.2.6 切换数据源
通过点击数据源右侧的按钮可以切换该数据集的数据源,如下图所示。
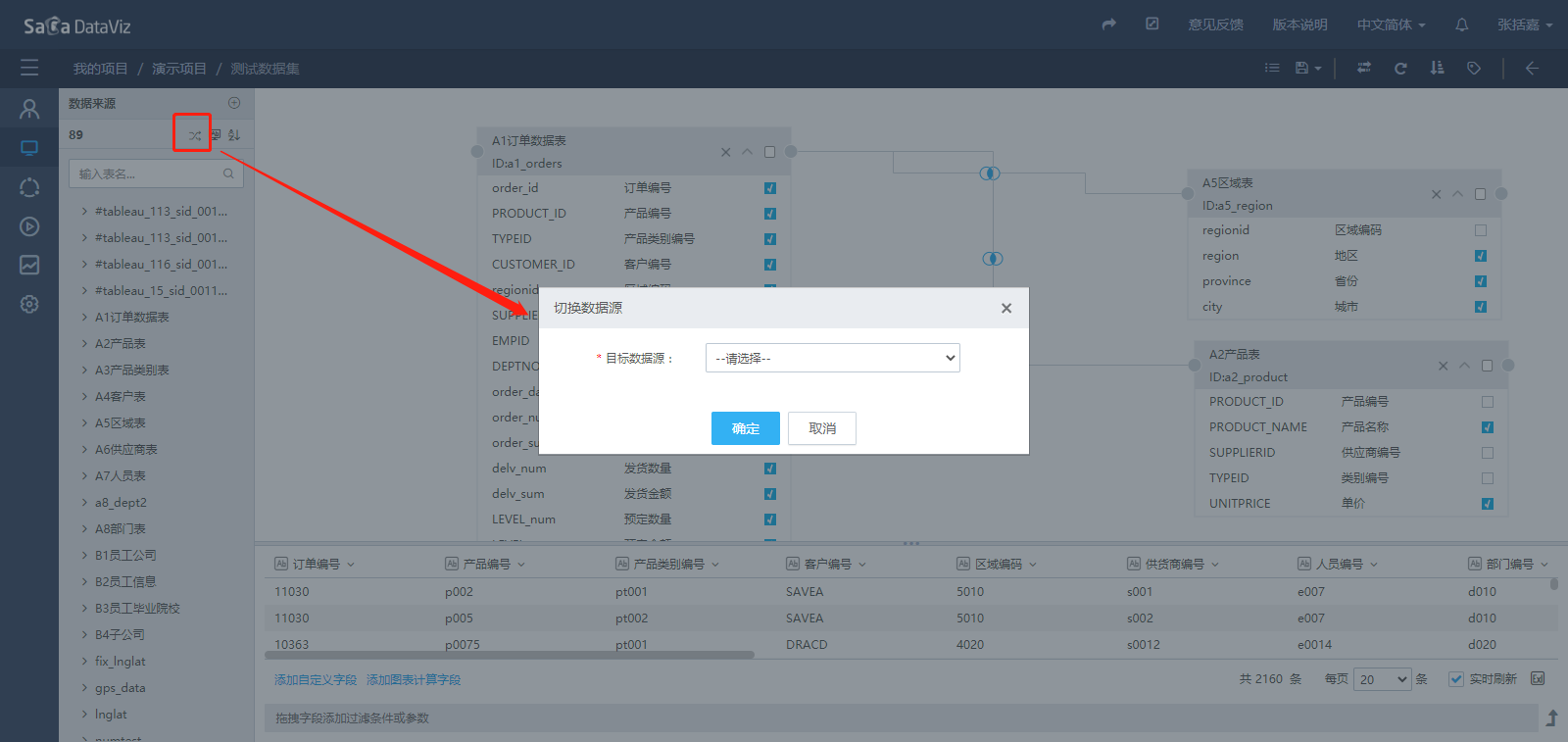
【注意】切换数据源需要保证两个数据源中的表结构完全一致,包含:表名,字段名以及字段类型等。